CHAPTER 6 Interpreting Medical Data
Effective data interpretation is a habit: a combination of knowledge, skill, and desire.1 By applying the seven habits (Table 6-1) outlined in this chapter, any otolaryngologist—regardless of his or her level of statistical knowledge or lack thereof—can interpret data. The numerous tables that accompany the text are designed as stand-alone reminders, and often contain keywords with definitions endorsed by the International Epidemiological Association.2
Table 6-1 The Seven Habits of Highly Effective Data Users
| Habit | Underlying Principles | Keywords |
|---|---|---|
| 1. Check quality before quantity. | All data are not created equal; fancy statistics cannot salvage biased data from a poorly designed and executed study. | Bias, accuracy, research design, confounding, causality |
| 2. Describe before you analyze. | Special data require special tests; improper analysis of small samples or data with an asymmetric distribution gives deceptive results. | Measurement scale, frequency distribution, descriptive statistics |
| 3. Accept the uncertainty of all data. | All observations have some degree of random error; interpretation requires estimating the associated level of precision or confidence. | Precision, random error, confidence intervals |
| 4. Measure error with the right statistical test. | Uncertainty in observation implies certainty of error; positive results must be qualified by the chance of being wrong; negative results by the chance of having missed a true difference | Statistical test, type I error, P value, type II error, power |
| 5. Put clinical importance before statistical significance. | Statistical tests measure error, not importance; an appropriate measure of clinical importance must be checked. | Effect size, statistical significance, clinical importance |
| 6. Seek the sample source. | Results from one data set do not necessarily apply to another; findings can be generalized only for a random and representative sample. | Population, sample, selection criteria, external validity |
| 7. View science as a cumulative process. | A single study is rarely definitive; data must be interpreted relative to past efforts, and by their implications for future efforts. | Research integration, level of evidence, meta-analysis |
The Seven Habits of Highly Effective Data Users
The seven habits that follow are the key to understanding data.3 They embody fundamental principles of epidemiology and biostatistics that are developed in a logical and sequential fashion. Table 6-1 gives an overview of the seven habits, as well as the corresponding principles and keywords that comprise them.
Habit 1: Check Quality Before Quantity
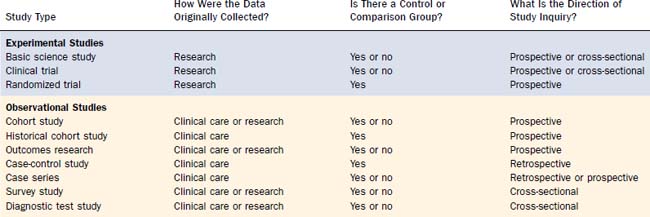
Bias is a four-letter word that is easy to ignore but difficult to avoid.4 Data collected specifically for research (Table 6-2) are likely to be unbiased—they reflect the true value of the attribute being measured. In contrast, data collected during routine clinical care will vary in quality depending on the specific methodology applied.
Table 6-2 Effect of Study Design on Data Interpretation
| Aspect of Study Design | Effect on Data Interpretation |
|---|---|
| How were the data originally collected? | |
| Specifically for research | Interpretation facilitated by quality data collected according to an a priori protocol |
| During routine clinical care | Interpretation limited by consistency, accuracy, availability, and completeness of the source records |
| Is the study experimental or observational? | |
| Experimental study with conditions under direct control of the investigator | Low potential for systematic error (bias); bias can be reduced further by randomization and masking (blinding) |
| Observational study without intervention other than to record, classify, analyze | High potential for bias in sample selection, treatment assignment, measurement of exposures, and outcomes |
| Is there a comparison or control group? | |
| Comparative or controlled study with two or more groups | Permits analytic statements concerning efficacy, effectiveness, and association |
| No comparison group present | Permits descriptive statements only, because of improvements from natural history and placebo effect |
| What is the direction of study inquiry? | |
| Subjects identified before an outcome or disease; future events recorded | Prospective design measures incidence (new events) and causality (if comparison group included) |
| Subjects identified after an outcome or disease; past histories examined | Retrospective design measures prevalence (existing events) and causality (if comparison group included) |
| Subjects identified at a single time point, regardless of outcome or disease | Cross-sectional design measures prevalence (existing events) and association (if comparison group included) |
Experimental studies, such as randomized trials, often yield high-quality data because they are performed under carefully controlled conditions. In observational studies, however, the investigator is simply a bystander who records the natural course of health events during clinical care. Although more reflective of “real life” than a contrived experiment, observational studies are more prone to bias. Comparing randomized trials with outcomes studies highlights the difference between experimental and observational research (Table 6-3).
Table 6-3 Comparison of Randomized Controlled Trials and Outcomes Studies
| Characteristic | Randomized Controlled Trial | Outcomes Study |
|---|---|---|
| Level of investigator control | Experimental | Observational |
| Treatment allocation | Random assignment | Routine clinical care |
| Patient selection criteria | Restrictive | Broad |
| Typical setting | Hospital or university based | Community based |
| End point definitions | Objective health status | Subjective quality of life |
| End point assessment | Masked (blinded) | Unmasked |
| Statistical analysis | Comparison of groups | Multivariate regression |
| Potential for bias | Low | Very high |
| Generalizability | Potentially low | Potentially high |
The presence or absence of a control group has a profound influence on data interpretation. An uncontrolled study, no matter how elegant, is purely descriptive.5 Nonetheless, authors of case series often delight in unjustified musings on efficacy, effectiveness, association, and causality. A case series is of greatest value when dealing with uncommon disorders or interventions, or with circumstances in which randomized trials would be unethical or impractical. The best case series include a consecutive sample of subjects, describe the sample fully, include details of interventions and adjunctive treatments, account for all participants enrolled (including withdrawals and dropouts), and ensure that follow-up duration is adequate to overcome random disease fluctuations.6
Without a control or comparison group, treatment effects cannot be distinguished from other causes of clinical change (Table 6-4). Some of these causes are seen in Figure 6-1, which depicts change in health status after a healing encounter as a complex interaction of three primary factors7–8:
Table 6-4 Explanations Other Than “Efficacy” for Outcomes in Treatment Studies
| Explanation | Definition | Solution |
|---|---|---|
| Bias | Systematic variation of measurements from their true values; may be intentional or unintentional | Accurate, protocol-driven data collection |
| Chance | Random variation without apparent relation to other measurements or variables; example: luck | Control or comparison group |
| Natural history | Course of a disease from onset to resolution; may include relapse, remission, and spontaneous recovery | Control or comparison group |
| Regression to the mean | Symptom improvement independent of therapy as sick patients return to a mean level after seeking care | Control or comparison group |
| Placebo effect | Beneficial effect caused by the expectation that the regimen will have an effect; example: power of suggestion | Control or comparison group with placebo |
| Halo effect | Beneficial effect caused by treatment novelty or by the provider’s manner, attention, and caring | Control or comparison group treated similarly |
| Hawthorne effect | Beneficial effect caused by the participant’s knowledge of being evaluated and observed in a study | Control or comparison group treated similarly |
| Confounding | Distortion of an effect by other prognostic factors or variables for which adjustments have not been made | Randomization or multivariate analysis |
| Allocation (susceptibility) bias | Beneficial effect caused by allocating subjects with less severe disease or better prognosis to treatment group | Randomization or comorbidity analysis |
| Ascertainment (detection) bias | Favoring the treatment group during outcome analysis; example: rounding up for treated subjects, down for controls | Masked (blinded) outcome assessment |
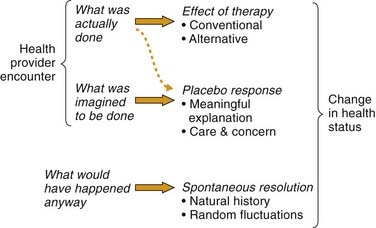
The placebo response differs from the traditional definition of placebo as an inactive medical substance. Whereas a placebo can elicit a placebo response, the latter can occur without the former. A placebo response results from the psychological or symbolic importance attributed by the patient to any nonspecific event in a healing environment. These events include touch, words, gestures, local ambience, and social interactions.10 Many of these factors are encompassed in the term caring effects,11 which have been central to medical practice in all cultures throughout history. Caring and placebo effects are so important that they have been deliberately used to achieve positive outcomes in clinical practice.12
When data from a comparison or control group are available, inferential statistics may be used to test hypotheses and measure associations. Causality may also be assessed when the study has a time span component, either retrospective or prospective (see Table 6-2). Prospective studies measure incidence (new events) whereas retrospective studies measure prevalence (existing events). Unlike time span studies, cross-sectional inquiries measure association not causality. Examples include surveys, screening programs, and evaluation of diagnostic tests. Experimentally planned interventions are ideal for assessing cause-effect relationships, because observational studies are prone to innate distortions or biases caused by individual judgments and other selective decisions.13
Another clue to data quality is study type,14 but this cannot replace the four questions in Table 6-2. Note the variability in data quality for the study types listed in Table 6-5, particularly the observational designs. Randomization balances baseline prognostic factors (known and unknown) among groups, including severity of illness and the presence of comorbid conditions. Because these factors also influence a clinician’s decision to offer treatment, nonrandomized studies are prone to allocation (susceptibility) bias (see Table 6-3) and false-positive results.15 For example, when the survival of surgically treated cancer patients is compared with the survival of nonsurgical controls (e.g., radiation or chemotherapy), without randomization, the surgical group will generally have a more favorable prognosis independent of therapy, because the customary criteria for operability (special anatomic conditions and no major comorbidity) also predispose to favorable results.
The relationship between data quality and interpretation is illustrated in Table 6-6 using hypothetical studies to determine whether tonsillectomy causes baldness. Note how a case series (examples 1 and 2) can have either a prospective or retrospective direction of inquiry depending on how subjects are identified; contrary to common usage, all cases series are not “retrospective reviews.” Only the controlled studies (examples 3 through 7) can measure associations, and only the controlled studies with a time span component (examples 4 through 7) can assess causality. The nonrandomized studies (examples 3 through 6), however, require adjustment for potential confounding variables—baseline prognostic factors that may be associated with both tonsillectomy and baldness and therefore influence results. As noted previously, adequate randomization ensures balanced allocation of prognostic factors among groups, thereby avoiding the issue of confounding.
Table 6-6 Determining If Tonsillectomy Causes Baldness: Study Design vs. Interpretation
| Study Design* | Study Execution | Interpretation |
|---|---|---|
| 1. Case series, retrospective | A group of bald subjects are questioned as to whether or not they ever had tonsillectomy. | Measures prevalence of tonsillectomy in bald subjects; cannot assess association or causality |
| 2. Case series, prospective | A group of subjects who had or who are about to have tonsillectomy are examined later for baldness. | Measures incidence of baldness after tonsillectomy; cannot assess association or causality |
| 3. Cross-sectional study | A group of subjects are examined for baldness and for presence or absence of tonsils at the same time. | Measures prevalence of baldness and tonsillectomy and their association; cannot assess causality |
| 4. Case-control study | A group of bald subjects and a group of nonbald subjects are questioned about prior tonsillectomy. | Measures prevalence of baldness and association with tonsillectomy; limited ability to assess causality |
| 5. Historical cohort study | A group of subjects who had prior tonsillectomy and a comparison group with intact tonsils are examined later for baldness. | Measures incidence of baldness and association with tonsillectomy; can assess causality when adjusted for confounding variables |
| 6. Cohort study (longitudinal) | A group of nonbald subjects about to have tonsillectomy and a nonbald comparison group with intact tonsils are examined later for baldness. | Measures incidence of baldness and association with tonsillectomy; can assess causality when adjusted for confounding variables |
| 7. Randomized controlled trial | A group of nonbald subjects with intact tonsils are randomly assigned to tonsillectomy or observation and examined later for baldness. | Measures incidence of baldness and association with tonsillectomy; can assess causality despite baseline confounding variables |
* Studies are listed in order of increasing ability to establish causal relationship.
Habit 2: Describe Before You Analyze
Describing data begins by defining the measurement scale that best suits the observations. Categorical (qualitative) observations fall into one or more categories and include dichotomous, nominal, and ordinal scales (Table 6-7). Numerical (quantitative) observations are measured on a continuous scale and are further classified by the underlying frequency distribution (plot of observed values vs. the frequency of each value). Numerical data with a symmetric (normal) distribution are symmetrically placed around a central crest or trough (bell-shaped curve). Numerical data with an asymmetric distribution are skewed (shifted) to one side of the center, have a sloping “exponential” shape that resembles a forward or backward J, or contain some unusually high or low outlier values.
Table 6-7 Measurement Scales for Describing and Analyzing Data
| Scale | Definition | Examples |
|---|---|---|
| Dichotomous | Classification into either of two mutually exclusive categories | Breastfeeding (yes/no), sex (male/female) |
| Nominal | Classification into unordered qualitative categories | Race, religion, country of origin |
| Ordinal | Classification into ordered qualitative categories, but with no natural (numerical) distance between their possible values | Hearing loss (none, mild, moderate), patient satisfaction (low, medium, high), age group |
| Numerical | Measurements with a continuous scale, or a large number of discrete ordered values | Temperature, age in years, hearing level in decibels |
| Numerical (censored) | Measurements on subjects lost to follow-up, or in whom a specified event has not yet occurred at the end of a study | Survival rate, recurrence rate, or any time-to-event outcome in a prospective study |
Depending on the measurement scale, data may be summarized using one or more of the descriptive statistics in Table 6-8. Note that when summarizing numerical data, the descriptive method varies according to the underlying distribution. Numerical data with a symmetric distribution are best summarized with the mean and standard deviation (SD), because 68% of the observations fall within the mean ± 1 SD and 95% fall within the mean ± 2 SD. In contrast, asymmetric numerical data are best summarized with the median, because even a single outlier can strongly influence the mean. If a series of five patients are followed after sinus surgery for 10, 12, 15, 16, and 48 months, the mean duration of follow-up is 20 months, but the median is only 15 months. In this case a single outlier, 48 months, distorts the mean.
Table 6-8 Descriptive Statistics
| Descriptive Measure | Definition | When to Use It |
|---|---|---|
| Central Tendency | ||
| Mean | Arithmetic average | Numerical data that are symmetric |
| Median | Middle observation; half the values are smaller and half are larger | Ordinal data; numerical data with an asymmetric distribution |
| Mode | Most frequent value | Nominal data; bimodal distribution |
| Dispersion | ||
| Range | Largest value minus smallest value | Emphasizes extreme values |
| Standard deviation | Spread of data about their mean | Numerical data that are symmetric |
| Percentile | Percentage of values that are equal to or below that number | Ordinal data; numerical data with an asymmetric distribution |
| Interquartile range | Difference between the 25th percentile and 75th percentile | Ordinal data; numerical data with an asymmetric distribution |
| Outcome | ||
| Survival rate | Proportion of subjects surviving, or with some other outcome, after a time interval (e.g., 1 year, 5 years) | Numerical (censored) data in a prospective study |
| Odds ratio | Odds of a disease or outcome in subjects with a risk factor divided by odds in controls | Dichotomous data in a retrospective or prospective controlled study |
| Relative risk | Incidence of a disease or outcome in subjects with a risk factor divided by incidence in controls | Dichotomous data in a prospective controlled study |
| Rate difference* | Event rate in treatment group minus event rate in control group | Compares success or failure rates in clinical trial groups |
| Correlation coefficient | Degree to which two variables have a linear relationship | Numerical or ordinal data |
* Also called the absolute risk reduction.
Although the mean is appropriate only for numerical data with a symmetric distribution, it is often applied regardless of the underlying symmetry. An easy way to determine whether the mean or median is appropriate for numerical data is to calculate both; if they differ significantly, the median should be used. Another way is to examine the SD; when it is very large (e.g., larger than the mean value with which it is associated), the data often have an asymmetric distribution and should be described by the median and interquartile range. When in doubt, the median should always be used over the mean.16
A special form of numerical data is called censored (see Table 6-7). Data are censored when three conditions apply: (1) the direction of study inquiry is prospective, (2) the outcome of interest is time-related, and (3) some subjects die, are lost, or have not yet had the outcome of interest when the study ends. Interpreting censored data is called survival analysis, because of its use in cancer studies where survival is the outcome of interest. Survival analysis permits full use of censored observations by including them in the analysis up to the time the censoring occurred. If censored observations are instead excluded from analysis (e.g., exclude all patients with less than 3 years of follow-up in a cancer study), the resulting survival rates will be biased and sample size will be unnecessarily reduced.
The odds ratio, relative risk, and rate difference (see Table 6-7) are useful ways of comparing two groups of dichotomous data.17 A retrospective (case-control) study of tonsillectomy and baldness might report an odds ratio of 1.6, indicating that bald subjects were 1.6 times more likely to have had tonsillectomy than were nonbald controls. In contrast, a prospective study would report results using relative risk. A relative risk of 1.6 means that baldness was 1.6 times more likely to develop in tonsillectomy subjects than in nonsurgical controls. Finally, a rate difference of 30% in a prospective trial or experiment reflects the increase in baldness caused by tonsillectomy, above and beyond what occurred in controls. No association exists between groups when the rate difference equals zero, or the odds ratio or relative risk equals one (unity).
Two groups of ordinal or numerical data are compared with a correlation coefficient (see Table 6-8). A coefficient (r) from 0 to 0.25 indicates little or no relationship, from 0.25 to 0.49 a fair relationship, from 0.50 to 0.74 a moderate to good relationship, and greater than 0.75 a good to excellent relationship. A perfect linear relationship would yield a coefficient of 1.00. When one variable varies directly with the other, the coefficient is positive; a negative coefficient implies an inverse association. Sometimes the correlation coefficient is squared (r2) to form the coefficient of determination, which estimates the percentage of variability in one measure that is predicted by the other.
Habit 3: Accept the Uncertainty of All Data
Uncertainty is present in all data, because of the inherent variability in biologic systems and in our ability to assess them in a reproducible fashion.18 If hearing in 20 healthy volunteers was measured on five different days, how likely would it be to get the same mean result each time? It is very unlikely, because audiometry has a variable behavioral component that depends on the subject’s response to a stimulus and the examiner’s perception of that response. Similarly, if hearing was measured in five groups of 20 healthy volunteers each, how likely would it be to get the same mean hearing level in each group? Again unlikely, because of variations between individuals. A range of similar results would be obtained, but rarely the exact same result on repetitive trials.
Uncertainty must be dealt with when interpreting data, unless the results are meant to apply only to the particular group of patients, animals, cell cultures, and DNA strands, in which the observations were initially made. Recognizing this uncertainty, each of the descriptive measures in Table 6-8 is called a point estimate, specific to the data that generated it. In medicine, however, one seeks to pass from observations to generalizations, from point estimates to estimates about other populations. When this process occurs with calculated degrees of uncertainty, it is called inference.
“Quite confident,” you reply. “There were five patients, four got better, and that’s 80%.”
Precision may be increased (uncertainty may be decreased) by using a more reproducible measure, by increasing the number of observations (sample size), or by decreasing the variability among the observations. The most common method is to increase the sample size, because the variability inherent in the subjects studied can rarely be reduced. Even a huge sample of perhaps 50,000 subjects still has some degree of uncertainty, but the 95% confidence interval will be quite small. Realizing that uncertainty can never completely be avoided, statistics are used to estimate precision. Thus when data are described using the summary measures listed in Table 6-8, a corresponding 95% confidence interval should accompany each point estimate.
Habit 4: Measure Error with the Right Statistical Test
To err is human—and statistical. When comparing two or more groups of uncertain data, errors in inference are inevitable. If one concludes that the groups are different, they may actually be equivalent. If one concludes that they are the same, a true difference may have been missed. Data interpretation is an exercise in modesty, not pretense—any conclusion we reach may be wrong. The ignorant data analyst ignores the possibility of error; the savvy analyst estimates this possibility by using the right statistical test.19
Now that we’ve stated the problem in English, let’s restate it in thoroughly confusing statistical jargon (Table 6-9). We begin with some testable hypotheses about the groups we are studying, such as “Gibberish levels in group A differ from those in group B.” Rather than keep it simple, we now invert this to form a null hypothesis: “Gibberish levels in group A are equal to those in group B.” Next we fire up our personal computer, enter the gibberish levels for the subjects in both groups, choose an appropriate statistical test, and wait for the omnipotent P value to emerge.
Table 6-9 Glossary of Statistical Terms Encountered When Testing Hypotheses
| Term | Definition |
|---|---|
| Central tendency | A supposition, arrived at from observation or reflection, that leads to predictions which can be tested and refuted |
| Null hypothesis | Results observed in a study, experiment, or test that are no different from what might have occurred due to chance alone |
| Statistical test | Procedure used to reject or accept a null hypothesis; statistical tests may be parametric, nonparametric (distribution-free), or exact |
| Type I (alpha) error |



