Care of the Professional Voice
Julina Ongkasuwan
Mark S. Courey
A thorough understanding of the principles of laryngeal anatomy, physiology, and sound production provides an excellent background on which to build diagnostic and therapeutic strategies for all types of laryngeal disorders. In the 21st century, it is no longer adequate for otolaryngologists to treat voice complaints differently in different types of voice users. Rather, the appropriate management for all voice disorders is based on a thorough understanding of voice-production principles. The otolaryngologist/laryngologist must have a basic understanding of voice requirements and physiologic demands for all patients from the child to the opera singer. With this knowledge, the otolaryngologist can make correct decisions in the management of all voice problems from transient edema secondary to overuse to the management of vocal fold lesions.
ANATOMY AND PHYSIOLOGY OF VOICE PRODUCTION
While details of laryngeal anatomy, development, and physiology have been previously presented, it is helpful to reemphasize certain concepts.
Extrinsic Laryngeal Musculature
The series of strap muscles attaching to the outside of the laryngeal framework are referred to as the extrinsic laryngeal musculature. These are paired and consist of the sternohyoid, sternothyroid, and thyrohyoid muscles (Fig. 72.1). They are innervated by the ansa cervicalis, which arises as a branch from cranial nerve (CN) XII. For the purposes of voice production, these muscles are believed to influence laryngeal position within the neck. Laryngeal position affects the length of the vocal tract, which in turn alters the resonance characteristics of the voice. It also should be noted that the tongue and floor of mouth musculature, including the paired digastric muscles, geniohyoid, genioglossus, hyoglossus, and mylohyoid, all attach to the top the external laryngeal framework on the hyoid bone. Although these are not part of the extrinsic laryngeal musculature, they influence the laryngeal position within the neck because of their attachment on the hyoid bone. These muscles also receive a portion of their motor innervation through branches of CN XII, and they function primarily to move the tongue for articulation of speech. Because both muscle groups controlling laryngeal height and articulation are innervated by the same motor system, overlap or stimulus generalization may occur during speech production. To produce a balanced or pleasing sound, the professional voice user must learn to control laryngeal height for resonance separately from the tongue movement for speech articulation (1).
It also is important to consider the pharyngeal musculature. The inferior constrictor attaches to the posterior aspect of the thyroid framework. This muscle plays a role in shaping the pharynx during speech production and, along with the middle and superior constrictor, also alters laryngeal height and closure patterns. The constrictors receive motor innervation from branches of CN X, which also controls the intrinsic laryngeal musculature. Therefore, stimulus generalization also may occur as the professional voice user attempts to separate intrinsic laryngeal function from pharyngeal shape and laryngeal height for resonation characteristics.
Intrinsic Laryngeal Musculature
The paired intrinsic muscles attach to the arytenoids and the cricoid and thyroid cartilages. As are most muscles, they are named for the origins and insertions. First, the thyroarytenoid (TA) muscles originate near the most anterior portion of the thyroid cartilage and insert on the side of the vocal process of the arytenoid and the middle and upper body (Fig. 72.2). This muscle is innervated by CN X.
Through muscular activation, the distance between the arytenoid and thyroid cartilages is shortened. This occurs primarily by pulling the arytenoid forward on the cricoid ring. As the distance shortens, the mucosal membrane overlying the muscle is thickened, and the extracellular matrix proteins are brought into the closer approximation with each other. The thickening of the tissue will affect its characteristics of vibration.
Through muscular activation, the distance between the arytenoid and thyroid cartilages is shortened. This occurs primarily by pulling the arytenoid forward on the cricoid ring. As the distance shortens, the mucosal membrane overlying the muscle is thickened, and the extracellular matrix proteins are brought into the closer approximation with each other. The thickening of the tissue will affect its characteristics of vibration.
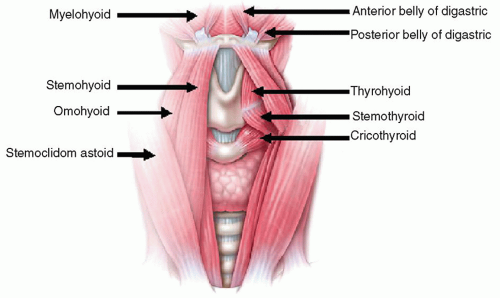 Figure 72.1 Extrinsic laryngeal musculature. |
The lateral cricoarytenoid (LCA) muscle originates on the lateral aspect of the cricoid ring and the inserts onto the muscular process of the arytenoid (Fig. 72.2). These paired muscles receive motor innervation through CN X. As the muscle contracts, the muscular process is pulled laterally and inferiorly. This action displaces the vocal process medially and inferiorly because of the angle of the cricoarytenoid joint. As the vocal fold adducts, the anterior aspect remains fixed at the anterior portion of the thyroid cartilage, but the posterior aspect moves inward and inferiorly.
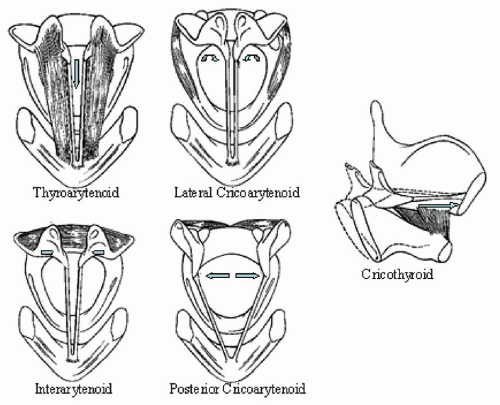 Figure 72.2 Intrinsic laryngeal muscles. |
The interarytenoid (IA) muscle is also innervated by CN X and attaches to the upper bodies of the arytenoid on the posterior and medial surfaces (Fig. 72.2). The muscle fibers run both obliquely and transversely. As the IA contracts, the upper portions of the arytenoid bodies tilt toward the midline. This action approximates the tissue slightly above the plane of the vocal process. In men, with thick mucosa and large cartilaginous structures secondary to the androgenic effects of testosterone, the entire space between the vocal processes is obliterated. In women, with more delicate structures, because of the relatively limited androgen effects of estrogen, the space is not filled or obliterated completely and is often viewed as an opening behind the vocal process or is referred to as an “open posterior chink.” This phenomenon has been reported in up to 76% of middle aged women (Fig. 72.3) (2).
The posterior cricoarytenoid is the only abductor of the vocal fold. It originates on the posterior aspect of the cricoid
ring and attaches to the muscular process on the posterior aspect of the arytenoid (Fig. 72.2). Contraction, stimulated by the recurrent laryngeal nerve from CN X, results in medial and inferior displacement of the muscular process. This results in lateral and upward displacement of the vocal process and, with it, the posterior aspect of the vocal fold.
ring and attaches to the muscular process on the posterior aspect of the arytenoid (Fig. 72.2). Contraction, stimulated by the recurrent laryngeal nerve from CN X, results in medial and inferior displacement of the muscular process. This results in lateral and upward displacement of the vocal process and, with it, the posterior aspect of the vocal fold.
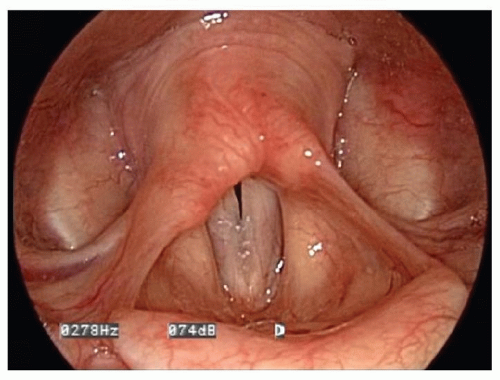 Figure 72.3 Posterior glottic chink. |
Finally, the cricothyroid (CT) muscle originates on the anterior aspect of the cricoid ring and attaches at the anterior aspect of the thyroid cartilage at the inferior tubercle (Fig. 72.2). Contraction is regulated by the external branch of the superior laryngeal nerve, which is a branch of CN X. As the CT muscle contracts, the thyroid lamina is pulled closer to the cricoid ring. The cricoid ring sits anterior to the thyroid lamina. As the thyroid lamina is displaced forward, the vocal fold is stretched. The action tenses the vocal fold and thins the mucosal cover, decreasing the mass of the vocal fold available to participate in the vibration. This is analogous to the action of a rubber band. As the rubber band is stretched, it becomes tenser, and its thickness or lateral dimension, and width or vertical dimension, are reduced.
Minor Intrinsic Laryngeal Cartilages
The minor intrinsic laryngeal cartilages, which include the corniculate, cuneiform, and epiglottis, do not function directly in voice production. Their presence most likely results in alteration of the configuration and stiffness of the vocal tract, which ultimately affects the shape and therefore the resonance quality of the vocal tract (1).
PRINCIPLES OF SOUND PRODUCTION
Sound production of all types requires three basic components: a power source, a vibratory source, and a resonator (Fig. 72.4). In human voice production, the exhaled air from the lungs serves as the power source that drives vocal fold vibration, the vibratory source. The true vocal folds produce a faint primary sounds source, which is then modulated by the third component, the resonating chamber or the supraglottic vocal tract. The supraglottic vocal tract is formed by the supraglottic larynx, the pharynx, and the oral cavity. If no resonating chamber were present, the primary sound source would produce a buzzing-type sound similar to a faint duck call.
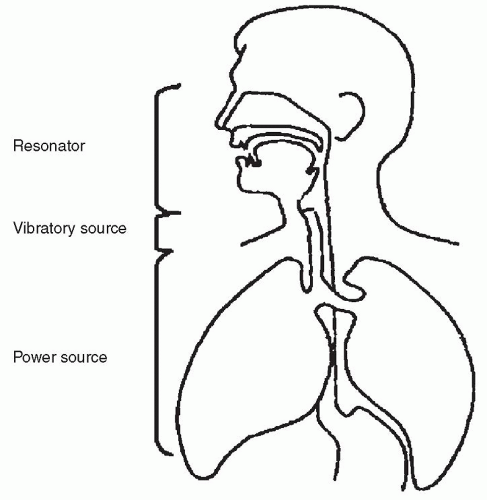 Figure 72.4 Vocal tract. |
Human communication can be divided into language, speech, and voice. Specifically, language production requires cognitive skills regulated by the cerebral cortex. Patients integrate higher cortical functions to express themselves through words and actions familiar to a certain region in which they were educated. Speech production refers to the articulation of words to produce language. It involves the supraglottic vocal tract for resonation and articulation of sounds produced at the glottis level. It is under the control of the cerebral cortex but is regulated by the coordinating centers in the basal ganglia and brain stem (3). Voice is produced through vocal fold vibration and specifically refers to the sound that emanates from the vocal folds as they are held in approximation and passively vibrated by the air that flows between them. Sounds produced by vocal fold vibration are termed voiced sounds. Commonly these are the vowels and voice consonants that require vocal fold adduction. Adduction and tension are regulated by cerebral cortical activity and are coordinated through the basal ganglia as well.
Harmonic Sound Source
Patients can present with problems of language, speech, voice, or a combination of these. In the professional voice user, we are most often concerned with problems of voice
production. Vocal fold vibratory activity is critical for voice production, as it provides the primary sound source, which is modulated by actions of the vocal tract (4). Vocal fold vibrations produce a complex tone. That is, they vibrate at a set of frequencies that have a whole-number mathematic relation between them. The primary frequency of vibration is termed the fundamental frequency (F0), and is closely related to the perceived pitch of the voice. Each wholenumber multiple of the F0 is called an overtone. The terminology is such that the F0 is labeled the first harmonic (H1), and each multiple of that frequency is the second, third, fourth, fifth harmonic (H2, H3, H4, H5, etc.), and so on to infinity (Table 72.1).
production. Vocal fold vibratory activity is critical for voice production, as it provides the primary sound source, which is modulated by actions of the vocal tract (4). Vocal fold vibrations produce a complex tone. That is, they vibrate at a set of frequencies that have a whole-number mathematic relation between them. The primary frequency of vibration is termed the fundamental frequency (F0), and is closely related to the perceived pitch of the voice. Each wholenumber multiple of the F0 is called an overtone. The terminology is such that the F0 is labeled the first harmonic (H1), and each multiple of that frequency is the second, third, fourth, fifth harmonic (H2, H3, H4, H5, etc.), and so on to infinity (Table 72.1).
TABLE 72.1 EXAMPLE OF FUNDAMENTAL FREQUENCY, OVERTONES, AND HARMONICS | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Formant Frequencies
The harmonic spectrum is presented to the vocal tract. Because of the length, shape, and distal opening of the vocal tract, certain of these harmonics are amplified or resonated, and others are dampened or attenuated (4). This pattern, known as the spectral envelope, creates the sounds that we hear in speech production. The amplified or resonated harmonic regions of the spectral envelope are called the formant regions. The first two formant regions are responsible for vowel differentiation, whereas the third through the fifth regions are responsible for the quality of the sounds (timbre). The different sounds of speech are produced by alterations in the length, shape, and mouth opening of the vocal tract. This is under voluntary control. The vocal professional learns to alter the shape of the vocal tract to produce the target sound quality.
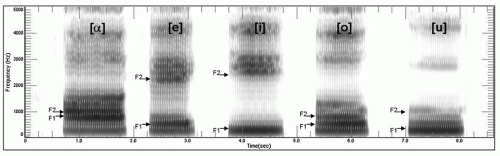 Figure 72.5 Spectrogram. |
The formant regions can be evaluated through spectral analysis of the vocal signal. The spectrogram is a visual representation of the audible sounds. It is a plot of frequency and intensity changes of sound over time (5). To produce a spectrogram, the sound emanating from the vocal tract is broken into various frequency regions as it is passed through a variable bandpass filter. The filter identifies the audible frequency regions between 0 and 8,000 Hz. The harmonic frequencies within this region are represented on the y-axis and time is represented on the x-axis. Intensity of the various harmonics is represented by darker frequency bands on the graph. The darker bands represent the amplified harmonics and are called the formant regions.
Vowels have characteristic first- and second-formant frequencies. These are represented as F1 and F2. The vowel is determined by the absolute F1 and F2 as well as the relative distance between them (Fig. 72.5). Harmonics are selectively amplified by changes in the length, shape, and distal opening characteristics of the vocal tract. The higher formants (F3 to F5) are responsible for the timbre of the sounds and differences in the sound characteristics between speakers. Classically trained singers learn to cluster the third, fourth, and fifth formant regions to amplify the harmonic sounds frequencies between 2,800 and 3,500 Hz (6). Amplified sound in this frequency range is preferentially detected by the human ear over other sounds. It is known as the singer’s formant, and is produced by learned behavior through which the classically trained singer, through movements in the tongue, pharynx, and lips, manipulates the vocal tract into a certain shape to amplify selectively the harmonics in the desired regions (7).
Although the quality of the spectral envelope is largely influenced by the shape, length, and distal opening of the vocal tract, it also is affected by the richness and quality of the harmonic spectrum presented to it as the sound source. Therefore, the vocal professional must be able to regulate
the harmonic source spectrum from the larynx, as well as the shape of the supraglottal vocal tract. Through manipulations of these two organ systems, all human speech sounds for professional and nonprofessional voice are produced (8).
the harmonic source spectrum from the larynx, as well as the shape of the supraglottal vocal tract. Through manipulations of these two organ systems, all human speech sounds for professional and nonprofessional voice are produced (8).
MECHANISM OF VOICE PRODUCTION
We previously discussed the actions of the supraglottic vocal tract. Specifically, in speech production, the speaker moves the tongue, pharynx, and lips to alter the shape, length, and distal opening of the vocal tract. In this manner, the formant regions are manipulated to amplify the desired harmonics produced by the sound source. The speaker also manipulates the sound source to enhance the harmonic spectrum presented to the vocal tract (9). Manipulation of the vibratory source is accomplished in all styles of voice production with the same basic mechanisms. These mechanisms include control of subglottic pressure, control of vocal fold approximation, and control of vocal fold tension (Table 72.2).
Subglottic Pressure
Subglottic pressure is the pressure immediately below the vocal folds during vocal fold vibration. It is generated by a combination of the force of the expelled air and by the force of vocal fold closure used to resist the outflow of the air (Fig. 72.6). Subglottic pressure correlates directly with the volume of the sound that is produced by the sound source (10). Sound is a disturbance in the pressure-density equilibrium of the atmosphere. Greater disturbances result in louder sounds. During the closed phase of vocal fold vibration, as the mucosal surfaces are approximated, the disturbance in the pressure -density equilibrium is minimal. As the air explodes through the glottis, the pressure-density disturbance is maximized. Higher subglottic pressures built up through prolonged closure explodes through the glottis and result in a more rapid change and a greater disturbance in the pressure-density equilibrium. Both the absolute degree of change and the rate of change are important. A louder sound source presents more intense harmonics to the resonating chamber. The spectral envelop is altered because the more intense harmonics are better amplified. In this manner, all of the formants, including those in the 2,800 to 3,500 Hz range, which are preferentially identified by the human ear, are amplified. Thus, all of the formants are boosted by a loud sound source (6).
TABLE 72.2 MANIPULATION OF THE VIBRATORY SOURCE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
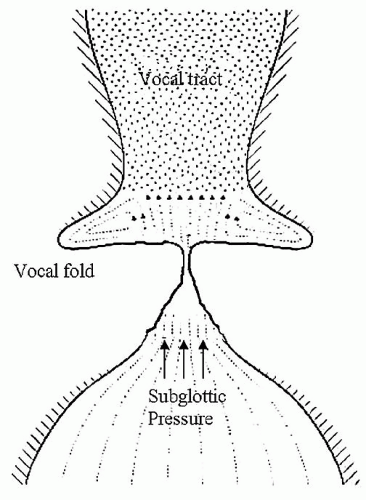 Figure 72.6 Subglottic pressure. |
Control of Subglottic Pressure with Respiratory Support
Singers can create more volume and therefore more amplification of the harmonics by increasing the subglottic pressure. Professional voice users, and all voice producers for that matter, control the rate of exhalation during voice production by allowing incremental relaxation of the muscles that expand the thorax. The diaphragm is the primary muscle used to expand the thorax. It is assisted by the actions of the intercostal muscles, which spread the ribs, and the spinal accessory muscles, which elevate the clavicles and first and second ribs. During inspiration, the thorax is expanded beyond its resting volume. Air is drawn into the lungs by the negative pressure created through expansion. As the diaphragm and intercostal muscles are relaxed, the thorax passively recoils to its resting size. During voice production, the rate of recoil is resisted through incremental relaxation of the muscles of inspiration and through contracting the muscles of the abdominal cavity. This phenomenon is referred to as respiratory support and is believed to be the most efficient mechanism for the regulation of subglottic pressure.
Control of Subglottic Pressure with Vocal Fold Contraction
However, during all types of voice production, increases in forces of vocal fold adduction, which resist air escape and overclose the larynx, can also be used to increase subglottic
pressure, and with it, the volume of the sound source. This mechanism for increasing subglottic pressure is believed to be inefficient and may result in excess muscular fatigue through hypercontraction of the TA muscles, LCA muscles, or both, which most often relax during phonation.
pressure, and with it, the volume of the sound source. This mechanism for increasing subglottic pressure is believed to be inefficient and may result in excess muscular fatigue through hypercontraction of the TA muscles, LCA muscles, or both, which most often relax during phonation.
Vocal Fold Approximation
Overclosure states, through a combination of hypercontraction of the intrinsic and extrinsic laryngeal musculature, can be used to augment the degree of laryngeal closure, affect the length of the closure phase during vibration, and alter the shape of the resonating vocal tract. Thus they affect the sounds spectrum through altering the sound source as well as the shape of the vocal tract.
Vocal Fold Tension
Finally, laryngeal tension for frequency of vibration and pitch control is under voluntary regulation. Tension is adjusted primarily by contraction of the CT muscle, which results in anterior displacement of the anterior commissure and elongating or stretching the vocal fold. In addition, CT contraction causes a reduction in vocal fold mass available to participate in vibration through thinning of the vocal cover as it is elongated. Both these actions result in pitch elevation.
The coordinated vocal user and particularly the vocal professional learn to control their vocal mechanism efficiently so that excess TA muscle contraction is not used to affect pitch. The vocal folds are set into a position for vibration. The relative tension for the desired frequency of vibration is set by tone in the CT muscle, which is termed prephonatory tuning, and then air is passed through the vocal folds, and vibration begins. During the sound-production phase, the TA muscle relaxes, and the vocal folds are held in nearly approximated position by the activity of the IA muscle. This activation pattern has been studied and documented through laryngeal electromyography (11).
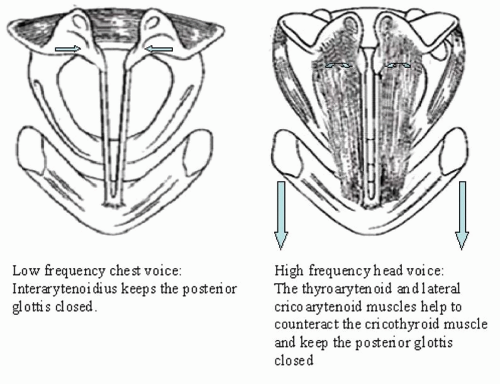 Figure 72.7 Using vocal fold tension to help control pitch. |
Vocal fold approximation, by the IA muscle, however, is opposed by activity of the CT muscle. As the CT contracts and the anterior portion of the TA is stretched forward, the posterior attachment to the arytenoids remains relatively fixed. Because the posterior border of the cricoid ring and the cricoarytenoid joint are angulated superiorly to inferiorly, continued unopposed contraction of the CT will lead to lateral displacement of the arytenoids and the posterior aspect of the vocal fold. As the vocal folds are spread apart by this action, the glottis width increases and vibration will stop unless the glottic distance is decreased through coordinated action of the intrinsic laryngeal musculature (LCA, TA) or the airflow from the lungs is increased (Fig. 72.7). Thus to maintain a continuum of pitches without allowing for a break in phonation, the coordinated vocal user balances the desired vocal fold tension against the abductory forces, so that the vocal folds maintain a nearly approximated aerodynamic position. In addition, the trained vocal professional is probably altering the speed of the air flow as well to help merge these vibratory ranges.
The vocal folds can be tensed and maintained in an artificially thick state. This will result in alterations of the vibratory patterns with prolonged closure. This prolonged closure phase will alter the sound source and may produce desirable harmonic characteristics. These intensified harmonics are more easily amplified by the vocal tract, and the singer’s formant region is boosted. Because of the boost in this region, the sound is preferentially distinguished as human and is enjoyable. This phenomenon is frequently used by female commercial vocalists as they attempt to sing in a relatively high-pitched, robust voice. It is referred to as “belting.” During belt voice production, a bright brassy sound is produced at the expense of laryngeal and cervical muscle hypercontraction. If the TA muscle is held overly tense during voicing, it may affect the vibratory characteristics of the
overlying vocal ligament and cover by not passively cushioning the vibratory forces. A stiff underlying TA may increase the shear or compressive stress placed on the overlying ligament and cover, thus increasing the likelihood of injury.
overlying vocal ligament and cover by not passively cushioning the vibratory forces. A stiff underlying TA may increase the shear or compressive stress placed on the overlying ligament and cover, thus increasing the likelihood of injury.
VOCAL PERFORMANCE STYLES
People perform by using both the speaking and singing voice. As covered in the last section, these sounds are produced by using the same anatomic and physiologic principles. The successful performer must be able to manipulate both the sound source and the resonating vocal-tract characteristics to produce sound of the desired style.
Voice Classification
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


