4
Sound Processors in Cochlear Implants
Ward R. Drennan and Jay T. Rubinstein
The sound processor provides the functional core of the cochlear implant, converting acoustic signals into electric signals. Sound processors have undergone extensive development over the past 40 years. Incremental improvements in hearing were achieved following each advancement. Sound processors evolved from single channel to multiple channels, from speech feature extractors to sound encoders, from simultaneous excitations to interleaved excitation, and from slow rates of presentation to high rates. From initial inception in the 1960s and early 1970s, the cochlear implant has changed from a device that provided merely a sensation of sound, improving acoustic awareness of the deaf, to a device that brings reliable speech understanding to the majority of users. Current research and development efforts continue to showimproved hearing with newsoundprocessing strategies.
Development of the cochlear implant has faced numerous challenges. First, hardware had to be developed that could safely deliver electrical signals into the inner ear. Second, processors had to be developed that could successfully transmit acoustic information to the auditory nerve. Third, the conditioners of the auditory systems in implant candidates are widely variable, so devices and processors had to be optimized to suit individuals. Outcomes were widely variable, yet, most users, particularly postlingually deafened adults and early-implanted deaf children, have enjoyed great benefit from their prostheses. This chapter reviews the historical development of sound processors and the current processing strategies, and highlights some promising new strategies.
♦ Single-Channel Implants
Early implants used a single channel. These implants provided some sensation of sound, but had extremely poor fidelity. The earliest single channel implant was the House/3M (St. Paul, MN) implant, developed by William F. House and his colleagues in Los Angeles, California. This single-channel implant succeeded in transmitting acoustic information electrically to the auditory nerve, but word recognition was not dramatically improved as there was minimal frequency-specific information delivered. A 16-kHz carrier provided a temporal envelope code that indicated when the sound was on or off. This could provide some periodicity information below 300 Hz,1 but the device did not perform any compression, causing substantial peak clipping. Duration and some voicing cues in speech were discernible. Although a few “star” listeners could understand speech, this device primarily provided acoustic awareness and served as an aid to lipreading.
In the early 1980s, the Vienna/3M single-channel implant became available. This device incorporated loudness control and compression.2,3 Compression minimized peak clipping and provided improved encoding for the temporal envelope. Nevertheless, minimal frequency information was available, so although outcomes improved,4,5 performance was still marginal.
♦ Representing Frequency Spatially
It has long been known that the inner ear functions, in part, as a frequency analyzer, transforming acoustic frequency to specific place along the basilar membrane.6 Although it was originally thought that an implant could not realistically achieve the fine frequency representation of 1000 inner hair cells, achieving some frequency representation was certainly possible. A linear array of electrode contacts was created and used to deliver multiple channels of current to different places along the basilar membrane dependent on the frequency of the input.
In the late 1970s and early 1980s, researchers in Australia introduced multichannel processors that extracted speech features from the acoustic input. For example, vowels are identified by the frequency of their spectral peaks (formants). This information could be delivered along with the fundamental frequency of the speaker (F0). (See The Handbook of Speech Perception7 for broad reviews of speech perception issues.) The F0/F2 processor8,9 identified an F0 and the second formant frequency (F2). F0, extracted with zero-crossings, determined the rate of electrical pulses delivered to a specific place corresponding to F2, re-creating the frequency encoding properties of the inner ear. The processing was implemented using a 22-channel cochlear implant. Such processing provided an improvement in performance over single-channel devices,10 but the scheme still provided only a fraction of the information present in the speech stimulus.
Developments in the early 1980s led to the F0/F1/F2 processing strategy, which became available in 1985.11 This processing scheme added first formant (F1) information. Central Institute for the Deaf (CID) sentence recognition more than doubled (from 16 to 35%) with the addition of the F1 component.12 Northwestern University (NU)-6 word recognition increased more than threefold (from 8 to 28%). The processing strategy did not incorporate higher-frequency consonant information, which could improve speech understanding further.
A new strategy called MultiPEAK (MPEAK) was introduced in the late 1980s. This approach used the F0/F1/F2 encoder and added high-frequency information in which consonants were encoded. Three high-frequency bands (2000–2800 Hz, 2800–4000 Hz, and >4000 Hz) were encoded using an envelope detector. This information was passed to the more basal electrodes using electric pulses. Performance again improved markedly with the additional information. Consonant identification improved from 17 to 28%.13 Sentence recognition also improved.14,15
These processors were intended to extract appropriate speech cues from the acoustic stimulus. If there was competing noise of any kind, particularly competing speech, the processors would often make errors in selection of the fundamental and formant frequencies. Later processors developed in Australia were also intended to encode speech, but they were not intended to extract specific speech cues.
♦ Compressed Analog and Continuous Interleaved Sampling
Concurrent with development of the Australian speech processors, a compressed analog (CA) strategy was developed in the United States.16,17 The processor was multichannel, using continuous and simultaneous current flow at each electrode. Originally, using the Ineraid (Richards, Salt Lake City, UT) device, the incoming acoustic wave was compressed, filtered into four channels, and passed via electrical current to the appropriate electrode. The approach incorporated compression using an automatic gain control (AGC) that compressed the wide acoustic dynamic range into the much more narrow electric dynamic range. Dorman et al18 reported a broad range of abilities ranging from 0 to 100% word recognition within CID sentences. Average performance was 45% correct, far exceeding performance with single-channel implants.
The Ineraid device is no longer available; however, CA processing is currently implemented in the form of the simultaneous analog strategy19 (SAS) with the Clarion (Advanced Bionics; Valencia, CA) device. SAS provided advancement over CA with a postfilter AGC, which limited spectral distortions caused by fast-acting compression implemented prior to filtering. SAS also used discrete current steps that change in intervals of 75 microseconds. The Clarion II can implement the SAS strategy with up to 16 channels. The CA and SAS approaches preserved the temporal waveform electrically including zero-crossings and temporal fine structure; however, users typically could perceive such fine structure only up to ˜300 Hz.1,20 Further, the simultaneous analog approach caused extensive channel interaction due to the summation of electric fields.21 This limited spectral resolution and the effectiveness of simultaneous analog approaches.
Wilson et al22 introduced continuous interleaved sampling (CIS), which addressed the problem of excessive channel interaction. CIS used rapid, nonsimultaneous sweeps of pulses across the electrode array to represent the time-varying acoustic spectrum. The incoming acoustic wave was filtered into multiple frequency channels corresponding to the number of electrodes. Then, the envelope of the wave was extracted using rectification and low-pass filtering. Finally, the amplitude envelopes were multiplied by nonsimultaneous biphasic pulse trains. Fig. 4–123 shows a schematic of the process. Extraction of frequency-specific amplitude modulations successfully transmitted spectral information but eliminated periodicity and temporal fine-structure at frequencies above the maximum frequency of the low-pass filter. The Hilbert transform, used in the modern Med-El (Innsbruck, Austria) devices, can also accomplish the same goal. The Hilbert transform converts the original acoustic wave into two outputs: an envelope and temporal fine structure. The envelope provides a smooth envelope extraction, without jaggedness. The extracted envelope is multiplied by a series of biphasic pulses that are passed to the appropriate electrodes in the implant after compression of the input into the dynamic range of the user. Empirical studies22 showed that speech can be understood well using the CIS approach. CIS often provided superior performance to SAS. All three implant companies offer CIS.
Several studies have compared SAS with interleaved strategies. The majority of people trying both strategies prefer CIS.24–26 CIS has often shown superior outcomes22; however, Battmer et al27 have shown that some SAS users can achieve excellent speech understanding. Osberger and Fisher26 showed no significant difference in performance after 6 months of experience but noted a faster learning rate among SAS users. Preferences fro CIS or SAS can depend upon the specific hardware used. For example, the Clarion “HiFocus” electrode array is designed to sit closer to the center of the cochlea. In a group of 56 Clarion HiFocus users, Zwolan et al28 reported that a majority preferred SAS. In another group of similar size that did not use HiFocus, the majority preferred CIS, as in the other studies. Zwolan et al speculated that the HiFocus array limited channel interaction, allowing better performance with SAS. There has not yet been a demonstration of broad clinical superiority for either strategy, but most implantees use some form of interleaved processing.
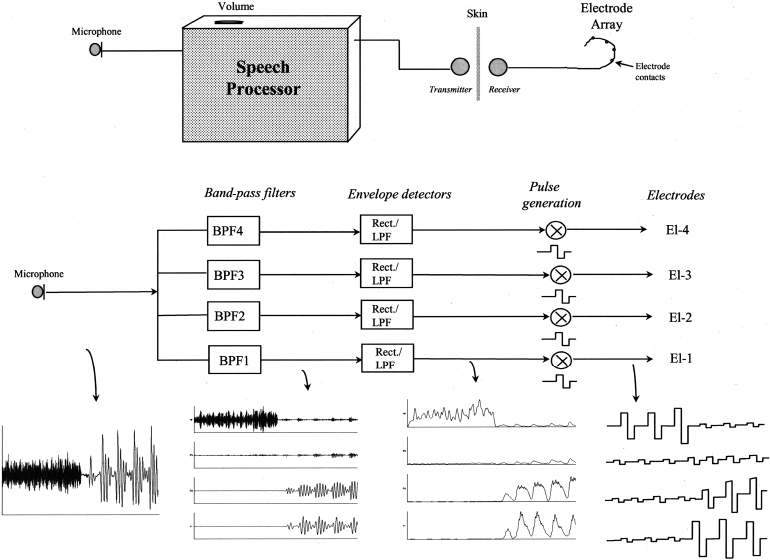
Figure 4–1 Top: Schematic of the cochlear implant. Middle: A more detailed schematic of the sound processor for continuous interleaved sampling (CIS). The input is filtered into four band-pass channels (only four channels are shown for simplicity). The band-pass outputs are rectified and low-pass filtered, creating a temporal envelope for each frequency band. The temporal envelopes are multiplied by nonsimultaneous biphasic pulse trains, which are delivered by electrical current through the cochlea via the electrode array. Bottom: The acoustic wave is transformed to a series of biphasic electrical pulses. (From Loizou P. Mimicking the human ear: an overview of signal-processing strategies for converting sound into electrical signals in cochlear implants. IEEE Signal Processing Magazine 1998;98:101–130, with permission.)
♦ Spectral Peak Processors
Building on the CIS concept, an “n-of-m” approach, in which m is the maximum number of electrodes available in the implant and n is the total number of channels, was developed.29 The Cochlear Corporation (Sydney, Australia) and Med-El (Innsbruck, Austria) devices currently use this approach. “n-of-m” worked much like CIS except that a subset of electrodes with the maximum filter output was selected for presentation. The Australian group developed the spectral maxima sound processor (SMSP).30 Sound was processed into 16 band-pass filters. Pulses were only delivered to the six channels having the maximum output. The current levels in filters with lower outputs were set to zero. Hence, n (6) of m (16) electrodes were activated on each sweep. The SMSP further reduced channel interaction. McKay et al31 showed that the processor provided markedly better speech recognition than speech-feature-extraction approaches (MPEAK).
The SMSP processor was developed into the spectral peak strategy (SPEAK), which is currently available with the Cochlear Corporation implants. In SPEAK, as with SMSP, a subset of electrodes was selected to present on each sweep, based on the filters with the largest outputs, i.e. the spectral peaks. The total numbers of maxima were selected from 20 channels. The number of peaks selected was variable, using up to 10 channels. Channels below a certain noise threshold would not be selected even if they were among the strongest 10. The approach conserved power and further limited channel interaction. SPEAK showed superior performance to MPEAK independent of evolving and more liberal candidature characteristics.32
The SPEAK processor operated at a slow pulse rate [250 pulses per second per channel (pps/ch)]. Higher pulse rates would be expected to improve the temporal encoding of the processed sounds. The Advanced Combination Encoder33 (ACE) was then implemented in the Nucleus (Cochlear Corporation, Englewood, CO) cochlear implants. ACE operated much like SPEAK, only using faster pulse rates. Evaluations of the ACE strategy have usually shown superior performance to SPEAK.34,35 Such improvements were shown independent of changing candidature.32 Most users preferred the ACE processing. The processing scheme that yielded the best speech perception performance usually corresponded with the preferred strategy. Kiefer et al34 noted that, given the fact that most users prefer ACE, it would be appropriate to use that in the initial fitting; however, they caution that variability among different users was great. Vandali et al,36 for example, noted wide variability in open-set speech recognition performance among five subjects with speech presented in multitalker noise. Loizou et al37 also reported between-listener variability dependent on pulse rates and pulse durations. Thus, for implant users, one pulse rate does not fit all. Individual optimization of pulse rate and pulse duration parameters can lead to significantly improved performance.
Other processing schemes have been implanted that combine simultaneous and successive pulsatile stimulation. The paired pulsatile sampler (PPS) enabled the presentation of two pulses simultaneously such that two simultaneous sweeps could occur. The separation of the active electrodes is kept wide as to still maintain minimal channel interactions. The quadruple pulsatile sampler is similar to the PPS, but four electrodes are stimulated simultaneously. A “hybrid” can provide SAS stimulation to the apical electrodes and CIS presentation to the basal electrodes. SAS can provide temporal fine-structure information. The auditory system can only encode such information at low frequencies, so the hybrid approach can be used to provide fine temporal information in the low frequencies while still minimizing channel interaction in the high-frequency region. Loizou et al38 compared these strategies. The results did not show many differences among strategies, but the participants did not have much experience with each strategy. Some trends were observed, however. Combination strategies can improve speech understanding over interleaved strategies or SAS alone. Further study will be required to document the extent to which these strategies might help over the long term.
♦ Further Improvements in Sound Processing
Ideally, an implant would perfectly re-create the neural excitation patterns of a normal-hearing person with acoustic stimulation. The implant achieves varying degrees of success depending on the type of information to be transferred.39 A cochlear implant has many limitations. First, the dynamic range in implants is highly limited, leading to complex issues regarding the manner of compression required. Second, the spectral-resolving power of implants is poor. Finally, the ability of implants to deliver temporal fine structure is highly limited.
Small dynamic ranges in cochlear implant users require extensive compression. To decrease the amount of compression, and to minimize background noise, the softest sounds are often eliminated. Processed quiet sounds can also be masked easily by louder sounds. James et al40 introduced adaptive dynamic range optimization (ADRO), which attempts to make all outputs comfortably loud. In doing so, ADRO increased the quieter speech sounds and improved intelligibility. With no background noise, ADRO improved open-set sentence recognition at low-to-moderate speech levels by 16 to 20%. Such increases in low-level pulses might reduce suprathreshold refractory effects, which can mask quiet sounds.41 Using another approach, Geurts and Wouters42 introduced “enhanced envelope” CIS (EECIS), which was intended to introduce rapid cochlear adaptation effects to electrical processing. EECIS could also increase lower level speech sounds (e.g., consonants). Word recognition ability was 7% better with EECIS than with CIS. The transient emphasis spectral maxima (TESM)43 approach was also intended to magnify short-duration speech cues that had low levels. Improvements in consonant and word recognition were observed with TESM. Additional improvements of about 9 to 11% were seen for half of the participants on sentence recognition in noise at 10 dB signal-to-noise ratio (S/N).
Other issues concerning dynamic range control involve the speed of compression and loudness balancing. Stone and Moore44 noted that the oft-used fast-action compression could reduce the ability of implantees to perceive amplitude modulations due to decreased modulation depth. Fast-action compression also increases comodulation across frequency channels, which could increase the likelihood of perceptual grouping of speech and noise,45 decreasing the ability of implantees to segregate sounds. Cochlear implant simulations presented to normal-hearing listeners showed improvement in sentence recognition in noise of ˜5%. McDermott et al46 noted that loudness summation is not considered when fitting implants. Typically, the threshold and maximum comfortable loudness level are set for each electrode individually. The summed loudness, however, when all electrodes are active can be much greater, depending on the pulse rate, the number of electrodes active, and on the individual listeners. The “SpeL” processing scheme was designed to match the loudness in implant users that normal hearing users would hear acoustically.46 Initial results have shown that SpeL improves audibility, but it has not yet been shown to improve speech recognition.47
The spectral resolving power of implant users is also limited. Fishman et al,48 Dorman et al,49 and Friesen et al,50 for example, found that despite having up to 22 processing channels, speech understanding does not improve significantly with more than about eight channels. Although eight channels is sufficient for good speech understanding in quiet conditions,51 more channels are needed for good speech understanding in noisy conditions50 and for good music perception.52,53 Several attempts have been made to increase the number of functional channels. These include the use of modiolar-hugging implants and the use of bipolar electrode configurations, which can decrease current spread within the cochlea. Neither of the approaches has yet to have a significant impact on clinical outcomes.13,54,55 One reason might be the compromised nerve survival of implant users.56–58 Ambitious work is being conducted to address this problem with investigations of nerve growth factors59–61 and hair cell regeneration.62–64 Although progress is encouraging, the amount of time required for development and approval of such future biological treatments is unknown. One approach with current technology involves improving the place coding of low frequencies using “current steering” by altering the current level balance between neighboring electrodes.65 Such adjustments lead to pitch changes and were shown to improve F0 discrimination ability.
The lack of ability of cochlear implants to pass the temporal fine structure of acoustic waves to the auditory nerve is yet another limitation. The ability to segregate speech from noise,66 perceive tonal speech,67 and hear musical melodies52,68 all rely heavily on temporal fine structure. Further, temporal fine structure is a critical element of binaural hearing in which interaural time differences are critical.69,70 For example, a cocktail party, with numerous competing speakers, is a serious problem for implant users. Implant listeners cannot easily pick out one speaker from another. The ability to segregate different fundamental frequencies (F0) is one critical element that helps listeners separate one speaker from another.71,72 Such information is encoded in the periodicity or pitch of the temporal fine structure.73 Delivery of temporal fine structure information could provide cues to speaker segregation based on periodicity. Binaural unmasking resulting from interaural time differences (ITDs) can provide additional benefit in a cocktail party situation.74 With bilateral implantation, temporal fine structure information could further improve speech understanding in noise with spatial separation. Zeng et al75 have shown, using cochlear implant simulations, that encoding frequency modulations can improve speech understanding in noise. Frequency modulations could be delivered with temporal fine structure.
There are three current processing strategies that could improve electrical delivery of temporal fine structure without greatly increasing channel interaction: (1) high pulse rates, >2000 pps; (2) combined acoustic and electric stimulation; and (3) use of a low-level, high rate conditioning stimulus. High pulse rates and combined acoustic and electric stimulation have already been implemented clinically. Use of a conditioning stimulus appears promising, but is still experimental.
Slower pulse rates used in SPEAK and ACE lead to highly synchronized firing of the auditory nerve. In the auditory nerve of a normal-hearing person, firing is not precisely synchronized, especially at low levels. Pulse rates greater than 2000 pps increase the probability of stochastic firing of nerves,21,76 decreasing the degree of synchronization. Each time a nerve fires, it undergoes a short refractory period during which it will not fire again. The refractory periods of nerves vary. At a slower pulse rate, all the nerves will recover and fire synchronously at the next pulse. If the rate is increased beyond ˜2000 pps, however, some nerves will be in the refractory period while others are not; thus a stochastic firing pattern could be introduced, making the electrically stimulated nerve respond more like an acoustically stimulated nerve.
The Clarion II processor (Advanced Bionics; Valencia, CA) can implement faster rates of stimulation, so a high resolution (HiResolution) strategy was introduced,25 employing many of the same principles as the CIS but using faster pulse rates. Frijns et al77 found that HiResolution led to better speech understanding in noise. The effectiveness of high rates varied with the number of electrodes stimulated. If the optimum number of electrodes was selected, nearly all users showed an improved ability to understand speech in noise. More dramatic results were documented by Koch et al,78 demonstrating improvements using Hearing in Noise Test (HINT) sentences presented at 10 dB S/N among listeners who had poor or average speech understanding ability. Most likely due to a ceiling effect, participants who were the best with slow pulse rates did not show much improvement with HiResolution; however, these listeners did report subjective benefit. The results with HiResolution show additional incremental improvements in speech understanding in noise, possibly because of improved encoding of temporal fine structure.
Combined electric and acoustic stimulation provides another approach to transmit temporal fine structure. Combined stimulation has been effective in patients who have some residual hearing and viable hair cells for stimulation.66,79 The fine structure is encoded in the normal way, via hair cell transmission. Combined stimulation can be achieved by using a hearing aid in one ear and an implant in the other,66,80 or by using a hearing aid and implant in the same ear with a short electrode array.79 Unfortunately, there are many patients with highly limited or nonexistent residual hearing. For these people, combined stimulation will be of no benefit.
Use of a “conditioning” or “desynchronizing” stimulus might also enhance transmission of temporal fine structure. A conditioning stimulus is a high-rate and low-level pulse train intended to encourage spontaneous activity in the nerve.76 The stimulus is designed to lightly activate the auditory nerve at all times, re-creating spontaneous activity like a normally functioning auditory nerve. Physiologic studies81 have shown that the use of a conditioner creates a more normal pattern of auditory nerve responses. Early psychophysical work with a conditioner has shown that the conditioner increases the dynamic range.82 These results are consistent with the presence of increased spontaneous activity in the auditory nerve. When implementing sound processing with a conditioner, less compression is required. Boike and Souza83 have shown that in hearing aids, increasing the dynamic range within a patient improves speech perception. The same might be true with an implant.
A conditioning stimulus can be added to any other processing scheme, for example, ACE, HiResolution, or SAS. Initial studies have shown that a conditioning stimulus provides significant and sometimes substantial benefit for understanding speech in noise for about one third of the patients who have tested the strategy. Conditioning was implemented in eight patients at the Leiden University Medical Center who were unilaterally implanted. A 5000-pps conditioner was applied to every other electrode in the electrode array. A 1000-pps/ch CIS was used on the nonconditioned electrodes. When fitting, the patients would hear the level of the conditioner initially, but they would adapt within a few minutes, so they did not chronically hear the conditioner. Of seven patients who completed the trial, two had remarkable performance with the conditioner, showing a 4-dB average improvement of speech reception threshold (SRT) in noise. In quiet conditions, speech understanding improved from 80 to 100% in both people. Three participants preferred the conditioner, but did not show objective benefit after 1 month. The remaining two listeners did not like the conditioner and returned to their clinical strategy. All listeners who continued to use the strategy after the initial fitting reported improved sound quality with the conditioner.
More recently, additional trials were conducted at the University of Iowa with continued encouraging results. Again, about one third of the participants had marked improvements in speech understanding in noise. One person, with the conditioner, had an SRT in babble noise of −9 dB, remarkable for an implant user and comparable to the SRT of person with a mild hearing loss. Two others showed significant objective improvements for speech understanding in noise, with SRTs improving from 5 to 19 dB. Three others preferred the conditioning strategy but did not show objective benefit, and three more did not like the conditioner and switched to their original strategy.
The conditioner has also been applied to two bilateral implant users. One of these patients did not like conditioning and opted for the clinical strategy. The second patient had highly asymmetric abilities. When the conditioner was added to the worse ear, this person’s ability to understand speech increased dramatically. The patient’s SRT in noise was +9 dB without the conditioner and −9 dB with the conditioner, an improvement of 18 dB. After 6 months of experience with the conditioner in one ear (with both implants operating) City University of New York (CUNY) sentence scores in noise (S/N = 10 dB) improved from less than 60 to 95%.
Thus, the conditioning approach shows substantial benefit in some patients, some benefit in others, and no benefit in still others. The reasons why some people glean substantial benefit and others do not are not yet known. Further research is required to determine these reasons and to determine the extent to which a conditioner can impact clinical outcomes. Clinical trials are required before the conditioning approach becomes commercially available.
♦ Conclusion
The first cochlear implants were single-channel devices that demonstrated the clinical viability of electrical stimulation of the auditory nerve. Users of single-channel devices had the benefit of acoustic awareness, but were usually poor at understanding speech. Later, multichannel devices were employed using simultaneous and successive electrical stimulation of the auditory nerve. Initial work included attempts to extract speech parameters from the acoustic stimulus. As a general rule, delivery of more speech information yielded a better clinical outcome. Later work showed that interleaved “peak-picking” strategies were more successful. These are currently implemented in the Med-El “n-of-m” strategy and in Cochlear Corporation’s SPEAK and ACE strategies. The primary limitation with these sound processors is the inability of users to recognize speech in noise, tonal speech, and musical melodies. These limitations likely result from the inability of the sound processors to transmit sufficient spectral resolution and temporal fine structure. Although physiologic limitations have slowed progress toward improving spectral resolution, approaches for improving the encoding of temporal fine structure have been implemented. HiResolution processing has been shown to improve speech understanding in noise. Additionally, for patients with some residual hearing, combined acoustic and electric stimulation has been shown to provide significant benefit. Future work includes the use of a conditioning stimulus to encourage more normal auditory nerve firing patterns. Although still experimental, a conditioning stimulus has provided improvements in about two thirds of cochlear implantees tested.
Acknowledgments
This work was supported by the VM Bloedel Hearing Research Center and National Institutes of Health (NIH) grant DC00242. Dr. Clifford Hume provided helpful comments on the text.
References
1. Zeng F-G. Temporal pitch in electric hearing. Hear Res 2002;174: 101–106
2. Hochmair ES, Hochmair-Desoyer IJ, Burian K. Investigations towards and artificial cochlear. Int J Artif Organs 1979;2:255–261
3. Hochmair ES, Hochmair-Desoyer IJ. Percepts elicited by different speech coding strategies. Ann N Y Acad Sci 1983;405:268–279
4. Hochmair-Desoeyer IJ, Hochmair ES, Stiglbrunner H. Psychoacoustic temporal processing and speech understanding in cochlear implant patients. In: Schindler R, Merzenich M, eds. Cochlear Implants. New York: Raven Press, 1985:291–304
5. Tyler RS. Open-set recognition with the 3 m/Vienna single-channel cochlear implant. Arch Otolaryngol Head Neck Surg 1988;114: 1123–1126
6. von Bekesy G. Experiments in Hearing. New York: McGraw-Hill, 1960
7. Pisoni DB, Remez RE, eds. The Handbook of Speech Perception. Malden, MA, Oxford, UK, Victoria, Australia: Blackwell, 2005
8. Tong YC, Clark GM, Seligman PM, Patrick JF. Speech processing for a multiple-electrode cochlear implant hearing prosthesis. J Acoust Soc Am 1980;68:1897–1899
10. Dowell RC, Clark GM, Seligman PM, Brown AM. Perception of connected speech without lipreading, using a multichannel hearing prosthesis. Acta Otolaryngol 1986;102:7–11
11. Blamey P, Dowell R, Clark GM. Acoustic parameters measured by a formant-estimating speech processor for a multiple-channel cochlear implant. J Acoust Soc Am 1987;82:38–47
12. Dowell RC, Seligman PM, Blamey P, Clark GM. Evaluation of a two-formant speech processing strategy for a multichannel cochlear prosthesis. Ann Otol Rhinol Laryngol 1987;96(suppl 128):132–134
13. von Wallenberg EL, Battmer RD. Comparative speech recognition results in eight subjects using two different coding strategies with the Nucleus 22 channel cochlear implant. Br J Audiol 1991;25: 371–380
14. Dowell RC, Dawson PW, Dettman SJ, et al. Multichannel cochlear implantation in children: a summary of current work at the University of Melbourne. Am J Otol 1991;12(suppl):137–143
15. Skinner MW, Holden LK, Holden TA, et al. Performance of postlinguistically deaf adults with the Wearable Speech Processor (WSP III) and Mini Speech Processor (MSP) of the Nucleus Multi-Electrode Cochlear Implant. Ear Hear 1991;12:3–22
16. Eddington DK. Speech discrimination in deaf subjects with cochlear implants. J Acoust Soc Am 1980;68:885–891
17. Merzenich MM, Rebscher SJ, Loeb GE, Byers CL, Schindler RA. The UCSF cochlear implant project. Adv Audiol 1984;2:119–144
18. Dorman MF, Hannley MT, Dankowski K, Smith L, McCnadless G. Word recognition by 50 patients fitted with the Symbion multichannel cochlear implant. Ear Hear 1989;10:44–49
19. Boex C, Balthasas Cd, Kos M-I, Pelizzone M. Electrical field interactions in different cochlear implant systems. J Acoust Soc Am 2003;114: 2049–2057
20. Shannon RV. Multichannel electrical stimulation of the auditory nerve in man. I. Basic psychophysics. Hear Res 1983;11:157–189
21. White MW, Merzenich MM, Gardi JN. Multichannel cochlear implants. Channel interactions and processor design. Arch Otolaryngol 1984;110:493–510
22. Wilson BS, Finley CC, Lawson DT, Wolford RD, Eddington DK, Rabinowitz WM. Better speech recognition with cochlear implants. Nature 1991;352:236–238
23. Loizou P. Mimicking the human ear: an overview of signal-processing strategies for converting sound into electrical signals in cochlear implants. IEEE Signal Process Mag 1998;15:101–130
24. Stollwerck LE, Goodrum-Clarke K, Lynch C, et al. Speech processing strategy preferences among 55 European CLARION cochlear implant users. Scand Audiol Suppl 2001;52:36–38
25. Frijns JHM, Briaire JJ, Laat JAPMd, Grote JJ. Initial evaluation of the Clarion CII cochlear implant: Speech perception and neural response imaging. Ear Hear 2002;23:184–197
26. Osberger MJ, Fisher L. New directions in speech processing: patient performance with simultaneous analog stimulation. Ann Otol Rhinol Laryngol 2000;185:70–73
27. Battmer RD, Zilberman Y, Haake P, Lenarz T. Simultaneous analog stimulation (SAS)–continuous interleaved sampler (CIS) pilot comparison study in Europe. Ann Otol Rhinol Laryngol Suppl 1999;177:69–73
28. Zwolan T, Kileny PR, Smith S, Mills D, Koch D, Osberger MJ. Adult cochlear implant patient performance with evolving electrode technology. Otol Neurotol 2001;22:844–849
29. Wilson BS, Finley CC, Farmer JC, et al. Comparative studies of speech processing strategies for cochlear implants. Laryngoscope 1988;98:1069–1077
30. McDermott HJ, McKay CM, Vandali AE. A new portable sound processor for the University of Melbourne/Nucleus Limited multielectrode cochlear implant. J Acoust Soc Am 1992;91:3367–3371
31. McKay CM, McDermott HJ, Vandali AE, Clark GM. A comparison of speech perception of cochlear implantees using the Spectral Maximum Sound Processor (SMSP) and the MSP (MULTIPEAK) processor. Acta Otolaryngol 1992;112:752–761
32. David EE, Ostroff JM, Shipp D, et al. Speech coding strategies and revised cochlear implant candidacy: an analysis of post-implant performance. Otol Neurotol 2003;24:228–233
33. King AJ, Kacelnik O, Mrsic-Flogel TD, Schnupp JW, Parsons CH, Moore DR. How plastic is spatial hearing. Audiol Neurootol 2001;6:182–186
34. Kiefer J, Hohl S, Stuerzebecher E, Pfennigdorff T, Gstoettner W. Comparison of speech recognition with different speech coding strategies (SPEAK, CIS and ACE) and their relationship to telemetric measures of compound action potentials in the Nucleus CI 24M cochlear implant system. Audiology 2001;40:32–42
35. Skinner MW, Holden LK, Whitford LA, Plant KL, Psarros C, Holden TA. Speech recognition with the Nucleus 24 SPEAK, ACE and CIS speech coding strategies in newly implanted adults. Ear Hear 2002;23: 207–223
36. Vandali AE, Whitford LA, Plant KL, Clark GM. Speech perception as a function of electrical stimulation rate: Using the Nucleus 24 cochlear implant system. Ear Hear 2000;21:608–624
37. Loizou PC, Poroy O, Dorman M. The effect of parametric variations of cochlear implant processors on speech understanding. J Acoust Soc Am 2000;108:790–802
38. Loizou PC, Stickney G, Mishra L, Assmann P. Comparison of speech processing strategies used in the Clarion implant processor. Ear Hear 2003;24:12–19
39. Moore BCJ. Coding of sounds in the auditory system and its relevance to signal processing and coding in cochlear implants. Otol Neurotol 2003;24:243–254
40. James CJ, Blamey PJ, Martin L, Swanson B, Just Y, Macfarlane D. Adaptive dynamic range optimization for cochlear implants: a preliminary study. Ear Hear 2002;23:49S–58S
41. Wieringen AV, Carlyon RP, Long CJ, Wouters J. Pitch of amplitude-modulated irregular-rate stimuli in acoustic and electric hearing. J Acoust Soc Am 2003;114:1516–1528
42. Geurts L, Wouters J. Enhancing the speech envelope of continuous interleaved sampling processors for cochlear implants. J Acoust Soc Am 1999;105:2476–2484
43. Vandali AE. Emphasis of short-duration acoustic speech cues for cochlear implant users. J Acoust Soc Am 2001;109:2049–2061
44. Stone MA, Moore BCJ. Effect of the speech of a single-channel dynamic range compressor on intelligibility in a competing speech task. J Acoust Soc Am 2003;114:1023–1034
45. Hall JW 3rd, Grose JH. Comodulation masking release and auditory grouping. J Acoust Soc Am 1990;88:119–125
46. McDermott HJ, McKay CM, Richardson LM, Henshall KR. Application of loudness models to sound processing for cochlear implants. J Acoust Soc Am 2003;114:2190–2197
47. McDermott HJ, Sucher CM, McKay CM. Speech perception with a cochlear implant sound processor incorporating loudness models. Acoustic Res Letters Online 2005;6:7–13
48. Fishman KE, Shannon RV, Slattery WH. Speech recognition as a function of the number of electrodes used in the SPEAK cochlear implant speech processor. J Speech Lang Hear Res 1997;40:1201–1215
49. Dorman MF, Loizou PC, Fitzke J, Tu Z. The recognition of sentences in noise by normal-hearing listeners using simulations of cochlear-implant signal processors with 6–20 channels. J Acoust Soc Am 1998;104:3583–3585
50. Friesen LM, Shannon RV, Baskent D, Wang X. Speech recognition in noise as a function of the number of spectral channels: comparison of acoustic hearing and cochlear implants. J Acoust Soc Am 2001;110:1150–1163
51. Shannon RV, Zeng F-G, Kamath V, Wygonski J, Ekelid M. Speech recognition with primarily temporal cues. Science 1995;270:303–304
52. Smith ZM, Delgutte B, Oxenham AJ. Chimaeric sounds reveal dichotomy in auditory perception. Nature 2002;416:87–90
53. Pfingst BE, Franck KH, Xu L, Bauer EM, Zwolan TA. Effects of electrode configuration and place of stimulation on speech perception with cochlear prostheses. J Assoc Res Otolaryngol 2001;2:87–103
54. Kileny PR, Zwolan TA, Telian SA, Boerst A. Performance with the 20 +2L lateral wall cochlear implant. Am J Otol 1998;19:313–319
55. Zwolan TA, Kileny PR, Ashbaugh C, Telian SA. Patient performance with Cochlear Corporation “20 + 2” implant: bipolar versus monopolar activation. Am J Otol 1996;17:717–723
56. Nadol JB, Xu WZ. Diameter of the cochlear nerve in deaf humans: implications for cochlear implantation. Ann Otol Rhinol Laryngol 1992;101:988–993
57. Hinojosa R, Lindsay JR. Profound deafness: associated sensory and neural degeneration. Arch Otolaryngol 1980;106:193–209
58. Otte J, Schunknecht HF, Kerr AG. Ganglion cell populations in normal and pathological human cochleae: implications for cochlear implantations. Laryngoscope 1978;88:1231–1246
59. Nakaizumi T, Kawamoto K, Minoda R, Raphael Y. Adenovirus-mediated expression of brain-derived neurotrophic factor protests spiral ganglion neurons from ototoxic damage. Audiol Neurootol 2004;9:135–143
61. Miller JM, Chi DH, O’Keeffe LJ, Kruszka P, Raphael Y, Altschuler RA. Neurotrophins can enhance spiral ganglion cell survival after inner hair cell loss. Int J Dev Neurosci 1997;15:631–643
62. Izumikawa M, Minoda R, Kawamoto K, et al. Auditory hair cell replacement and hearing improvement by Atoh1 gene therapy in deaf mammals. Nat Med 2005;11:271–276
63. Parker MA, Cotanche DA. The potential use of stem cells for cochlear repair. Audiol Neurootol 2004;9:72–80
64. Stone JS, Rubel EW. Cellular studies of auditory hair cell regeneration in birds. Proc Natl Acad Sci U S A 2000;97:11714–11721
65. Geurts L, Wouters J. Better place-coding of the fundamental frequency in cochlear implants. J Acoust Soc Am 2004;115:844–852
66. Kong Y-Y, Stickney GS, Zeng F-G. Speech and melody recognition in binaurally combined acoustic and electric hearing. J Acoust Soc Am 2005;117:1351–1361
67. Xu L, Pfingst BE. Relative importance of temporal envelope and fine structure in lexical-tone perception (L). J Acoust Soc Am 2003;114:3024–3027
68. Kong Y-Y, Cruz R, Jones JA, Zeng F-G. Music perception with temporal cues in acoustic and electric hearing. Ear Hear 2004;25: 173–185
69. Middlebrooks JC, Green DM. Sound localization by human listeners. Annu Rev Psychol 1991;42:135–159
70. Wightman FL, Kistler DJ. The dominant role of low frequency inter-aural time differences in sound localization. J Acoust Soc Am 1992;91:1648–1661
71. Summerfield Q, Assmann PF. Perception of concurrent vowels: effects of harmonic misalignment and pitch-period asynchrony. J Acoust Soc Am 1991;89:1364–1377
72. Culling JF, Darwin CJ. Perceptual separation of simultaneous vowels: within and across-formant grouping by F0. J Acoust Soc Am 1993;93:3454–3467
73. Faulkner A, Rosen S, Smith C. Effects of the salience of pitch and periodicity information on the intelligibility of four-channel vocoded speech: Implications for cochlear implants. J Acoust Soc Am 2000;108:1877–1887
74. Zurek PM. Binaural advantages and directional effects in speech intelligibility. In: Studebaker GA, Hochberg I, eds. Acoustical Factors Affecting Hearing Aid Performance, 2nd ed. Needham Heights, MA: Allyn and Bacon, 1993
75. Zeng F-G, Nie K, Stickney GS, et al. Speech recognition with amplitude and frequency modulations. Proc Natl Acad Sci U S A 2005;102: 2293–2298
76. Rubinstein JT, Wilson BS, Finley CC, Abbas PJ. Pseudospontaneous activity: stochastic independence of auditory nerve fibers with electrical stimulation. Hear Res 1999;127:108–118
77. Frijns JHM, Klop WMC, Bonnet RM, Briaire JJ. Optimizing the number of electrodes with high-rate stimulation of the Clarion CII cochlear implant. Acta Otolaryngol 2003;123:138–142
78. Koch DB, Osberger MJ, Segel P, Kessler D. HiResolutionTM and conventional sound processing in the HiResolutionTM Bionic Ear: using appropriate outcome measures to assess speech recognition ability. Audiol Neurootol 2004;9:214–223
79. Gantz BJ, Turner CW. Combining acoustic and electric hearing. Laryngoscope 2003;113:1726–1730
80. Tyler RS, Parkinson AJ, Wilson BS, Witt S, Preece JP, Noble W. Patients utilizing a hearing aid and a cochlear implant: speech perception and localization. Ear Hear 2002;23:98–105
81. Litvak L, Delgutte B, Eddington D. Improved neural representation of vowels in electric stimulation using desynchronizing pulse trains. J Acoust Soc Am 2003;114:2099–2111
82. Hong RS, Rubinstein JT. High-rate conditioning pulse trains in cochlear implants: dynamic range measures with sinusoidal stimuli. J Acoust Soc Am 2003;114:3327–3342
83. Boike KT, Souza PE. Effect of compression ratio on speech recognition and speech-quality ratings with wide dynamic range compression amplification. J Speech Lang Hear Res 2000;43:456–468
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


