Fig. 45.1
The two noise tokens used in the SSA experiments. (a) Waveforms of the first 30 ms of each of the two tokens. (b) Power spectra of the two tokens, calculated in 1/3 octave bands. (c) Spectrograms of the two tokens
The two word-like stimuli are presented in Fig. 45.2. They were synthesized using the default settings in the text-to-speech synthesizer, Festival (available in Linux, Fedora 14). The two words have been modified with the help of the vocoder STRAIGHT (Kawahara et al. 2008) using additional processing routines written by us. The frequency content of the two sounds was shifted to above 1 kHz, and the pitch contour was set to a constant 350 Hz. These modifications resulted in sounds that had some features of speech, notably strong spectro-temporal modulations in the speech range. We specifically equalized the peak energy (see Fig. 45.2a) and the overall power spectra (Fig. 45.2b) of the two stimuli. Their spectro-temporal modulations are, however, different (Fig. 45.2c).
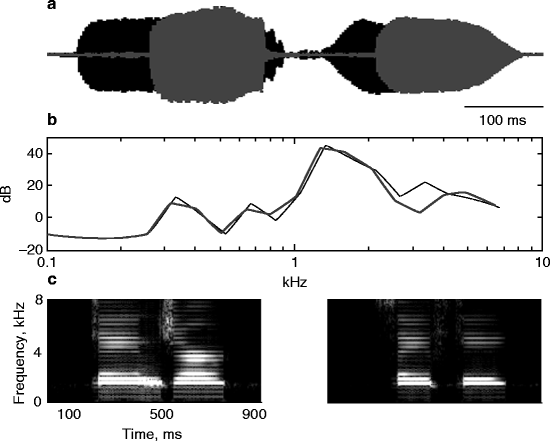
Fig. 45.2
The two word-like stimuli used in the SSA experiments. (a) Waveforms of the two stimuli (black: “danger,” gray: “safety”). (b) Power spectra of the two stimuli, calculated in 1/3 octave bands (same color convention). (c) Spectrograms of the two stimuli (left: “danger,” right: “safety”)
The two white noise tokens were used as the common and rare stimuli in oddball sequences. Two sequences were used, with each token playing both roles. The responses of three multiunit clusters to the two tokens are displayed in Fig. 45.3a–c. Figure 45.3a shows the responses of a multiunit cluster that responded essentially identically to the two tokens when common and when rare. Figure 45.3b shows the responses of a multiunit cluster that showed substantial reduction in the response to a token when common, relative to the response to the same token when rare. This is a somewhat extreme example – in most multiunit clusters, the effect was more subtle, as illustrated in Fig. 45.3c. The differences between the responses to a token when common and when rare are significant but small. Note in addition that the enhanced responses to a token when common and when rare had to a large extent the same time course. On the other hand, the responses to the two different tokens could follow quite different time courses (and have quite different overall magnitude).
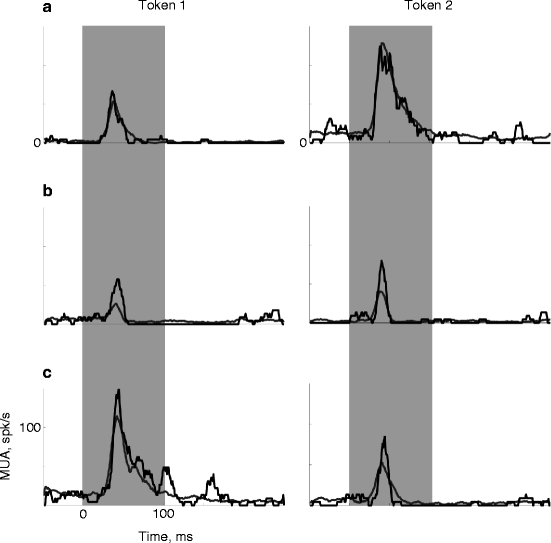
Fig. 45.3
MUA elicited by the two noise tokens when used as common (gray lines) and rare (black lines) sounds in oddball sequences. (a–c) responses at three recording sites
The word-like stimuli had a longer duration and were presented at a substantially lower rate (ISI of 1,200 ms) than the white noise tokens. Nevertheless, they elicited differential responses when used in oddball sequences, with each of the stimuli tested both as standard and as deviant. Examples of local field potentials recorded in response to the word-like stimuli are shown in Fig. 45.4. The major component of the responses to both words occurred at about the time of the major amplitude transient into the first vowel. The peak-to-peak amplitudes of the responses were larger when stimuli were rare than when common, although both the response itself and the contrast between common and rare responses were larger for the word-like stimulus derived from “safety” than for the stimulus derived from “danger.” The response to “safety” (top) may have included another response component at offset, although its significance is difficult to establish.
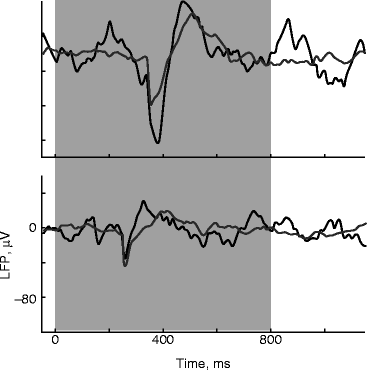
Fig. 45.4
LFP elicited by the two word-like stimuli (top: “safety,” bottom: “danger”) when used as standards (gray lines) and deviants (black lines)
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


