Fig. 41.1
Cortical reconstruction of each of two competing speech streams. (a) The correlation between neural reconstruction and the actual envelope of each speaker (filled and hollow symbols for attended and unattended speakers, respectively). The two speakers are shown by circles and diamonds, respectively. The correlation with each speaker is normalized based on the correlation at 0 dB TMR when the speaker is attended. (b) The AIF for each speaker, under each attentional state. The x-axis is the stimulus intensity and the y-axis is the dimensionless amplitude of the neural reconstruction on a linear scale. The level difference between the speakers is indicated by the line style
The TMR-independent neural reconstruction implies neural compensation for the intensity change of the speakers. This is further investigated using the AIF, which describes the relationship between the instantaneous amplitude of the neural response and the instantaneous intensity of the stimulus envelope (Fig. 41.1b). The AIFs for the two speakers show distinct behaviors. The AIF for the varying-intensity speaker shifts leftwards as the intensity of the speaker decreases, regardless of the attentional state of the listener. A leftward shift of the AIF indicates an increase in response gain since lower intensity is needed to achieve a given response amplitude. When fitted by a line, the AIF shifts 6.0 ± 0.2 dB and 5.0 ± 1.1 dB (Mean ± SEM) for the attended and unattended speaker, respectively, as the intensity of the speaker changes by 8 dB. The AIF for the constant-intensity speaker, in contrast, is not significantly affected by the intensity change of varying-intensity speaker. Therefore, the neural representation of each speaker only adapts to the mean intensity of that speaker, rather than the mean intensity of the stimulus mixture. In other words, neural adaptation to sound intensity is auditory stream specific.
3 Cortical Representation of Speech Masked by Noise
3.1 Methods
In the speech-in-noise experiment (Ding and Simon 2013), each stimulus consisted of a 50-s duration spoken narrative. Stationary noise matching the long-term spectrum of speech was generated using a 12th-order linear predictive model and mixed into speech with one of the following six TMRs: quiet, +6, +2, −3, −6, and −9 dB. The intensity of speech was the same for all stimuli while the intensity of the noise varied. Ten subjects participated.
Each stimulus (12 in total) was presented three times. The TMR always increased or decreased every two sections (counterbalanced over subjects). The subjects were asked a comprehension question after each section. During the first presentation of each stimulus, the subjects were asked to rate the intelligibility of each stimulus. The order how the sections were presented, whether with increasing or decreasing TMR, did not affect speech intelligibility (two-way repeated-measures ANOVA, factors: TMR, Order) or the neural reconstruction of speech (the same ANOVA) and therefore was not distinguished in the analysis.
3.2 Results
To investigate how the cortical representation of speech is affected by background noise, we reconstructed the temporal envelope of the underlying clean speech, not the actual stimulus, from the cortical response to a noisy stimulus (Fig. 41.2). The correlation between the neural reconstruction and the actual envelope of speech remains high until the TMR drops to −9 dB (Fig. 41.2). This indicates that, above −9 dB, the temporal modulations of speech are cortically encoded by phase-locked activity, regardless of the degradation caused by noise. Decoding accuracy was not affected by TMR when the −9 dB condition is excluded (2-way repeated-measures ANOVA, factors: TMR, Trial).
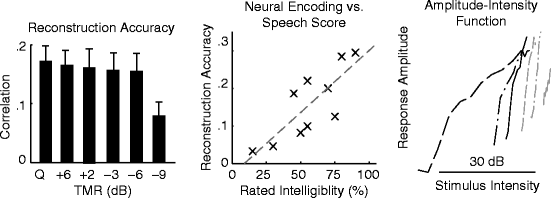
Fig. 41.2
Neural reconstruction of speech masked by stationary noise. (Left) The correlation between the neural reconstruction and the temporal envelope of the underlying clean speech. (Middle) At −3 dB TMR, individual subject’s intelligibility rating is significantly correlated with the accuracy of neural reconstruction. (Right) The AIF for each TMR condition. The curves, from left to right, correspond to conditions with decreasing TMR
At the intermediately low TMR of −3 dB, the median of the rated speech intelligibility was 55 % and varied widely. At this TMR, individual subject’s subjectively rated speech intelligibility is significantly correlated with neural reconstruction accuracy (R = 0.78 ± 0.15, bootstrap, Fig. 41.2). No such correlation was found at high and low TMRs, because of ceiling (median >90 %) and floor (median ≤10 %) effects in the ratings.
Stationary background noise reduces the depth of the spectro-temporal modulations, i.e., intensity contrast, of speech. Therefore, the robust neural encoding of speech suggests that the loss of stimulus contrast is compensated for by the auditory system. To demonstrate this, we estimated the AIF for each TMR condition and found the AIF to be strongly TMR dependent (Fig. 41.2), showing neural adaptation to intensity contrast. The slope of the AIF, extracted by a linear regression, increases 16 ± 2 dB (Mean ± SEM) as TMR decreases from infinity (quiet) to −6 dB.
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


