Fig. 49.1
(a) Results for Experiment 1. Voice recognition performance is plotted as mean d′ over the group of listeners (N = 14) as a function of the gate duration. Given the number of trials, the maximum possible d′ is 4.1. Error bars represent the standard error about the mean. (b) Median excitation patterns and interquartile range (voice: dark gray; instruments: light gray) for the 8-ms gate duration (see text for details)
Voices could be recognised significantly better than chance right from the shortest duration tested, i.e. a raised-cosine window of 2-ms length in total [t(13) = 4.3, p < 0.001].
2.3 Interim Discussion
The present results confirm and extend previous findings (Gray 1942; Robinson and Patterson 1995): here, recognition of very short sounds still occurs (1) for a relatively diverse set of natural recordings (2) for durations smaller than the pitch period (3) with gate onsets chosen randomly within the sounds. It should be noted that the minimum duration observed should, in all likelihood, depend on the stimulus set investigated. In particular, we selected a voice-detection task that seems to be particularly easy for human listeners, at least for longer sounds (Agus et al. 2012). In any case, the good performance obtained for relatively short sounds (d′ > 1 for 8 ms and above) enables the design of the rapid sequential paradigm of Experiments 2 and 3.
We calculated excitation patterns for the target and distractor categories (gammatone filterbank followed by half-wave rectification, low-pass filtering, and logarithmic compression; Patterson et al. 1995). Results are illustrated in Fig. 49.1b, for the 8-ms gate duration; results with other gate durations are not shown but they were similar. While it is clear that there must be some spectral cues that listeners used to perform the task, at least for the shorter durations, it does not appear that these cues are trivially simple given the large overlap between interquartiles (see also Agus et al. 2012, for further acoustic analyses of the sound set).
3 Experiments 2 and 3: Rapid Audio Sequential Presentation (RASP)
3.1 Methods
The 14 listeners of Experiment 1 were divided in two groups: 8 listeners took part in Experiment 2 and 6 listeners took part in Experiment 3.
Gated sounds were generated as in Experiment 1. These sounds were presented in sequences that differed in terms of their SOAs and number of sounds.
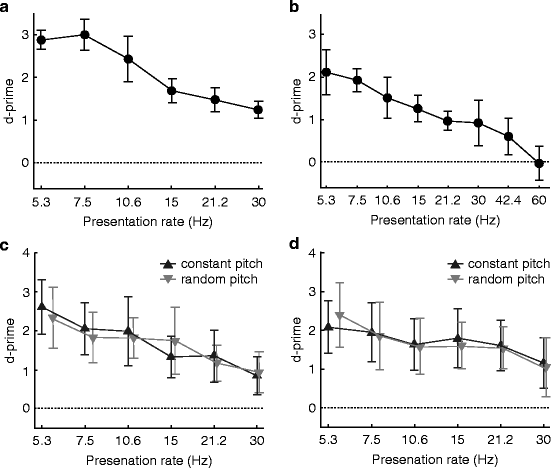
In Experiment 2, all sequences had a fixed duration of 500 ms. In half of the blocks, they were composed of 32-ms sounds; in the other half of the blocks, 16-ms sounds were used. For the 32-ms sequences, the presentation rate (sounds per second, or equivalently 1/SOA) varied between 5.3 and 30 Hz on a logarithmic scale. For the 16-ms sequences, the rate varied between 5.3 and 60 Hz. Nontarget trials were composed of musical instruments only. For target trials, one sound of the sequence was a voice sound, at a random position but not first or last. Sound sources in the sequences were chosen randomly from the distractor and target sets, as appropriate, with pitch also chosen randomly for each sound.
In Experiment 3, two experimental factors were tested: the number of sounds and the pitch relation between sounds. Sequences could have either a fixed duration (500 ms, as in Experiment 2) or a fixed number of sounds (7 sounds). The pitch for each sound in the sequence could either be drawn randomly for each sound (as in Experiment 2) or pitch was held constant for all sounds throughout a sequence (the pitch value was drawn randomly for each sequence). For this experiment, only the 32-ms sounds were used.
The same apparatus as in Experiment 1 was used.
Participants had to indicate whether each sequence included a voice sound. Target sequences containing a voice sound were presented 50 % of the time. Visual feedback was provided after each response. Prior to the experiments, participants performed a short training session, including easier sequences composed of 64-ms sounds.
In Experiment 2, the two types of sequences (16 and 32 ms) were tested in separate blocks, always in the same order, with the 32-ms sequences first. The 16-ms sequences were included in the design as it appeared that listeners performed the task above chance for the shortest possible SOA (30 Hz) with the 32-ms sounds (see Sect. 3.2.1). Within a block, the presentation rates were randomised. For each condition, 60 repetitions were collected per participant.
In Experiment 3, the two types of sequences were tested in separate blocks: sequences with a fixed duration and sequences with a fixed number of sounds. Within each block, we compared the two pitch conditions, fixed or random. The 6 (rate) × 2 (pitch) conditions were presented in a random order. For each condition, 60 repetitions were collected per participant.
Performance was again evaluated with d′. The assumption was made that listeners performed their judgment on a “voice” signal dimension, without any correction for the number of non-voice sounds presented (which could vary from trial to trial because of the presentation rate). For Experiment 2, two participants had an unusual pattern of results: their sequence performance was poor, for all presentation rates, even though they had good performance for the recognition of sounds presented in isolation (Experiment 1). These participants were excluded from further analysis.
3.2 Results
3.2.1 Experiment 2
Results are displayed in Fig. 49.2a, b. As expected, as the rate of the sequence increased, performance decreased. For the 32-ms and 16-ms sound duration sequences separately, data were analysed with a repeated-measures ANOVA with presentation rate as the within-subjects variable. For both type of sequences, the ANOVA revealed a significant main effect of rate [32 ms: F(5,25) = 21.35, p < 0.001; 16 ms: F(7,35) = 14.97, p < 0.001].