Fig. 56.1
Seating layout of the virtual restaurant
Speech reception thresholds (SRTs) were measured using an adaptive method similar to that used by Hawley et al. (2004) in which listeners increase the level of the first sentence until they judge it intelligible. The method differed in two important respects from that used in previous studies. First, stimulus uncertainty was maintained by selecting the interfering complexes at random from the set available for that condition in the preparation of each stimulus. Second, the adaptive algorithm automatically rejected completely incorrect transcripts as responses to the first target sentence. This procedure prevented participants starting the adaptive track at an inappropriately low target-to-masker ratio after inadvertently transcribing one of the interfering sentences. Sixteen participants each attended a single 90-min session. Following two practice measurements, the 16 conditions were presented in a pseudorandom order, which was rotated for each successive participant. Target speech materials remained in the same order. Participants were advised that the target speech would be heard located in the middle, would begin about half a second after the interfering speech, and whether it was the same or a different voice from the interferers.
In one experiment, interfering sources either were the same male voice as the target or were speech-shaped noises. There were 16 conditions (2 interferer types × 2 levels of reverberation (anechoic/reverberant) × 4 numbers of interfering sources). In a second, all interfering sources were a different male voice from the target voice, and there were eight conditions (2 levels of reverberation, anechoic/reverberant × 4 numbers of interfering sources).
3 Results
Figure 56.2 shows the results from the first experiment. Overall, SRTs increased with the number of interfering voices (F(3, 45) = 433, p < 0.0001), were higher in reverberation than in an anechoic space (F(1, 15) = 276, p < 0.0001), and were higher for speech interferers than for noise interferers (F(1,15) = 129, p < 0.0001). However, some strong interactions were present.
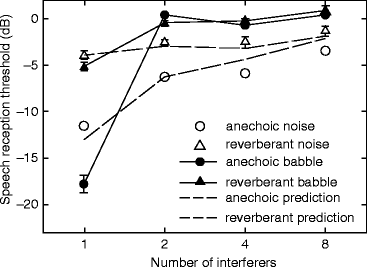
Fig. 56.2
Speech reception threshold as a function of number of interferers for different masker and room types. Error bars indicate one standard error
The effect of the number of interfering sources was much stronger for speech interferers than for noise interferers (F(3, 45) = 66, p < 0.0001); for speech interferers in anechoic conditions, SRT increased by 18 dB when a second interferer was introduced, even though the 3 dB increase in level from adding a second source had been compensated at the point of stimulus preparation. For noise, this increase was only 5 dB. Further increases in the number of interferers had little effect. In reverberant conditions, the effect was significantly smaller (F(3, 45) = 44, p < 0.0001). Overall, reverberation had marginally less effect on SRTs with speech interferers than with noise interferers (F(1, 15) = 16.5, p < 0.05). The effect of the number of interfering sources was also stronger in anechoic than in reverberant conditions (F(3, 45) = 130, p < 0.0001), because SRTs for a single interferer were substantially elevated by reverberation, while SRTs for multiple interferers were less elevated.
The effects of reverberation were well predicted by the Jelfs et al. (2011) model for noise interferers (dashed lines in Fig. 56.1). In contrast, the model overestimated SRTs for a single speech interferer and underestimated SRTs for multiple speech interferers.
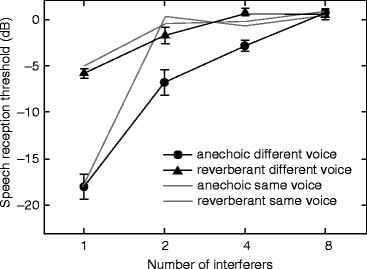
Fig. 56.3
Speech reception thresholds as a function of number of interferers for different rooms and for same-voice interferers (grey, reproduced from Fig. 56.2) and different voice interferers (black). Error bars indicate one standard error
Figure 56.3 shows the results when the target voice was a different male voice from the interferers. For comparison, the results using the same voice as the target are reproduced from Fig. 56.2 as grey lines. There is very good agreement between the two experiments for 1 and 8 interferers, but for 2 and 4 interferers, there seems to be an advantage for listening to different voices. A between-subjects analysis of variance comparing the second experiment with the first tested the effect of having a different voice for target and interferer. SRTs were lower overall with different voices (F(1, 22) = 76, p < 0.02). This effect was significant only in the two-interferer case (F(1, 88) = 36, p < 0.0001) and was larger in anechoic conditions, producing interactions between interferer voice and number of interferers (F(3, 22) = 39, p < 0.0001) and a three-way interaction including reverberation (F(3, 66) = 27, p < 0.0001).
4 Discussion
The most striking feature of the results is the dramatic increase in SRT with two speech interferers rather than one. In anechoic conditions, this increase was 18 dB. A number of factors probably contribute to this increase, including a loss of SRM, an inability to exploit F0 differences between multiple concurrent sources, reduced opportunity for dip listening, and increased IM.
When only one interferer is present, SRM is strong because the interferer comes from one side, while the target speech is in front. A second interferer from the opposite hemifield reduces SRM. The benefit of better-ear listening to SRM can be largely abolished in the latter case (Hawley et al. 2004; Culling et al. 2004). Binaural unmasking will be less affected; the Jelfs et al. model predicts that better-ear listening will be reduced by 5 dB, but binaural unmasking by only 0.4 dB. The combined influence of these two effects can be seen in the results for noise interferers, which are well predicted by the model.
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


