Fig. 14.1
Average sentence recognition scores as a function of SNR env with SNR tfs as parameter. The vocoder condition (Voc) is also plotted as a parameter. Error bars indicate one standard deviation
3 Role of the Target and Masker Fine Structure
Experiment 1 showed that stimuli with only the TFS of the target (i.e., 1,000 dB SNR tfs ) are not more intelligible than those with only the TFS of the masker (i.e., −1,000 dB SNR tfs ). The results of this experiment, however, should not be taken to imply that the target and the masker TFS make equal contribution to speech recognition in noise. The fact that they were obtained with vocoder-like stimuli (i.e., stimuli having a single carrier) strongly limits their applicability to situations in which both carriers are preserved. Moreover, it may be assumed according to the results of previous TFS studies that the TFS of the target is more important than that of the masker. This assumption is based on the finding that vocoder processing is more detrimental to speech recognition in fluctuating than in steady backgrounds, suggesting that it is when the representation of the masker is poorest (i.e., in the masker dips) that the benefit from preserved target TFS is the largest.
A study by Apoux and Healy (2011) recently assessed this assumption. The authors manipulated independently the TFS of the target and that of the masker to evaluate their individual contributions to speech recognition in noise. This evaluation included four masker types: a speech-shaped noise (SSN), a speech-modulated noise (SMN), a time-reversed sentence (TRS), and a sentence (SPE). All four maskers were added to the target /a/-consonant-/a/ stimuli at −6 or 0 dB SNR. For each combination of masker type and SNR, four processing conditions were implemented. A first condition, referred to as UNP, consisted of the unprocessed stimuli. The remaining conditions involved vocoder processing. In one condition, only the target was vocoded (VOC t ). In another condition, only the masker was vocoded (VOC m ). In the last condition, the entire sound mixture was vocoded (VOC tm ). This last condition is analogous to the traditional vocoder condition.
Consonant identification scores averaged across 20 normal-hearing listeners are shown in Fig. 14.2. Because the patterns were very similar for the two SNRs, only the data from the −6 dB condition are presented. As pointed out by the authors, two patterns emerged from these data. One pattern was only observed in the SSN condition. It involved no effect (i.e., scores equivalent to UNP) of vocoding only the masker (VOC m ) or the entire sound mixture (VOC tm ). The fact that scores were not reduced as a result of VOC tm in steady noise is consistent with previous TFS work. More surprisingly, this pattern also involved an effect of vocoding only the target (VOC t ). The other pattern involved a drop in intelligibility when vocoding only the target (VOC t ) or the entire sound mixture (VOC tm ). The fact that scores were reduced as a result of VOC tm in modulated noise is also consistent with previous TFS work. Again, no effect of vocoding only the masker was observed. The statistical significance of all the above effects was confirmed by a multiple pairwise comparison (corrected paired t-tests).
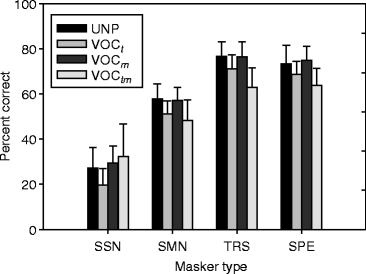
Fig. 14.2
Average percent correct scores for consonant identification as a function of masker type with VOC processing as parameter (unprocessed (UNP), target only (VOC t ), masker only (VOC m ), and entire stimulus (VOC tm )). Error bars indicate one standard deviation
One interpretation of the above data is that the normal auditory system does not rely heavily on the nature of the masker TFS to extract speech from noise. Most of the segregation cues seem to be provided by the target signal. In other words, listeners would tend to focus on the TFS of the target signal to uncover the time-frequency regions containing a relatively undistorted view of local signal properties, the so-called glimpses (Cooke 2006; Apoux and Healy 2009). The glimpses would be subsequently used to form a representation of this target signal. Logically, this strategy is no longer effective when the TFS of the entire sound mixture is vocoded (VOC tm ). More surprisingly, the strategy also seems to fall apart when only the target is vocoded. While this last result may be interpreted as evidence that speech information is conveyed by the TFS, it may simply reflect a better “extractability” of the original speech TFS.
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


